|
In data warehouse technology, a multiple dimensional view can be implemented by a relational database technique (ROLAP), or by a multidimensional database technique (MOLAP), or a hybrid database technique (HOLAP). (a) Briefly describe each implementation technique. The following three different types of OLAPs represent the middle tier of the three-tier data warehouse server architecture. ROLAP (Relational OLAP servers): Intermediate servers that are found between relational back-end server and client front-end tools. They make use of RDBMSs or extended RDBMSs to store/manage warehouse data + OLAP middleware to fill in the gaps. ROLAP servers have the ability to optimize the all back end DBMSs, as well as deployment of “aggregation navigation logic,” and other tools/services. ROLAPs tend to be more scalable than MOLAP. Explain how each of the following functions may be implemented: i. The generation of a data warehouse (including aggregation). Initial aggregation may be accomplished in SQL via group-bys. The compute cube operator computes aggregates over all subsets of the dimensions in the specified operation; this leads to the generation of a single cube. ROLAP relies on tuples and relational tables as its basic data structures. The base fact table (a relational table) stores data at the abstraction level indicated by join keys in the schema for the given data cube. Aggregated data can also be stored in fact tables (summary fact tables). ROLAP uses value-based addressing, where dimension values are accessed via key-based addressing search strategies. To optimize ROLAP cube computation we may use the following techniques: - sorting, hashing, grouping operations ii. Roll-up: Aggregation on a data cube (aka dimension reduction). In
ROLAP, this means that the relational tables are aggregated from more
to less specific.
iii. Drill-down: The opposite of Roll-up. We introduce additional dimensions into the relation tables and, hence, cubes.
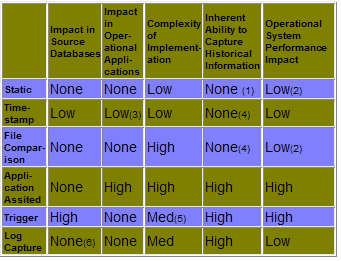
iv. Incremental updating: Data warehouse implementation can be broken down into segments or increments. An increment is a defined data warehouse implementation project that has a specified beginning and end. An increment may also be referred to as a departmental data warehouse within the context of an enterprise. A ROLAP server would take require the use of appropriate tools such as those made by Informix. Since ROLAPs are based on relation databases, the updating method would (I think) be performed in a manner similar to those in traditional RDBMS, and then grafted onto the data cube(s). Some of the techniques are summarized in this article from the above link: Incremental data capture is a time-dependent model for capturing changes to operational systems. This technique is best applied in circumstances where changes in the data are significantly smaller than the size of the data set for a specific period of time (i.e., the time between captures). These techniques are more complex than static capture, because they are closely tied to the DBMS or the operational software which updates the DBMS. Three different techniques in this category are application-assisted capture, trigger-based capture and transaction log capture. In circumstances where DBMSs are used to store operational data, transaction log capture is the most powerful and provides the most efficient approach to incremental capture. Some of the incremental techniques used are listed in Figure 1 below. FIGURE 1: Incremental Update Techniques
MOLAP (Multidimensional OLAP servers): These servers allow for multidimensional views of data through “array-based multidimensional engines.” They can map multidimensional views onto data cube arrays. The advantage to this is quicker indexing to pre-computed summarized data. MOLAPs may have a two-level storage system in order to handle sparse and dense data – dense “subcubes” are identified/stored as array structures; sparse “subcubes” use compression to make storage more efficient. Explain how each of the following functions may be implemented: i. The generation of a data warehouse (including aggregation). MOLAP uses array structures to store data for OLAP. Initial aggregation may be accomplished in SQL via group-bys. The compute cube operator computes aggregates over all subsets of the dimensions in the specified operation; this leads to the generation of a single cube. MOLAP follows very different cube computation scheme than ROLAP. It uses direct array addressing, where dimension values are accessed via the position or index of the corresponding array. The approach to generate an array-based cube is as follows: - Partition array into chunks. A chunk is a subcube that is small enough
to fit into the memory for cube computation. ii. Roll-up: The Roll-up method for MOLAPs would be somewhat similar to the process described above for ROLAP. Except, now, we are rolling up chunks that make up the subcubes…and rolling up the subcubes that make up the array. iii. Drill-down: The opposite of roll-up. We introduce additional dimensions into the subcubes or array. iv. Incremental updating. Please see “Incremental Updating” for ROLAPs. The technique for MOLAP updates would be more sophisticated due to the additional complexity of arrays and subcubes. Selecting the right tools would seem to be the key. An example would be Microsoft Data Warehousing Framework and OLAP Manager which is included with SQL Server OLAP Services. HOLAP (Hybrid OLAP servers): Basically, a combination of ROLAP and MOLAP. The benefits: a combination of greater scalability of ROLAP and faster computation of MOLAP. Example: a HOLAP can allow lots of detailed data to be stored in a RDBMS while aggregations are stored in a separate MOLAP. Explain how each of the following functions may be implemented: i. The generation of a data warehouse (including aggregation). The generation would consist of a combined approach of both MOLAP and ROLAP. A HOLAP would be generated to store large volumes of detail in a relational database (see i. for ROLAP generation methods) while a MOLAP would be used to store aggregations separately (see i. for MOLAP generation methods) ii. Roll-up. A combination of ROLAP and MOLAP roll up methods (See above). iii. Drill-down. A combination of ROLAP and MOLAP roll up methods (See above). iv. Incremental updating. A combination of ROLAP and MOLAP roll up methods (See above).
i. The generation of a data warehouse (including aggregation): see above ii. Roll-up: see above iii. Drill-down: see above iv. Incremental updating: see above Which implementation do you prefer? I would have to say that the Hybrid approach seems to be the best solution for most applications. It would appear to be backward compatible with older(?) ROLAPs and retains the scalability of this implementation. At the same time, it incorporates the more sophisticated features and faster computation of MOLAP. Describe the eight-layer Data Warehouse Architecture. Operational Database / External Database Layer: The operational system is the system that handles the organization’s day-to-day transactions (the operational database may be part of a DBMS, too). Operational systems have limited focus. Hence, connecting (or integrating) the data warehouse system to the operational database must be done with careful planning. Additionally, an organization may acquire data from an outside source. Information Access Layer: this is the layer that the user deals directly with. It consists of the tools the end-user uses every day. Examples: Excel spreadsheets, Lotus, MS Access, etc. This layer also includes the hardware/software for handling printing and displaying reports, charts, etc. Data Access Layer: this layer lets the Info Access Layer (above) to talk to the Operational Layer. The way it “speaks” is by the use of SQL. The Data Access Layer spans different DBMSs and file systems on the same hardware as well as providing universal access via the use of various protocols. It, theoretically, has the capability to access all the info out there in the enterprise. Data Directory (Meta) Layer: Universal data access (as described above) needs some type of data directory or repository of meta-data info (data about data). In addition, the fully functional warehouse must have meta data of many varieties, data about end-users views and data about the operational databases. This layer gives the end user the ability to access data from the warehouse (or operational databases_ w/o having to know where that data is actually located or the form in which it is stored. Process Management Layer: this layer deals with scheduling the various tasks that must be done to create/maintain the warehouse and data directory info. This layer schedules/controls high-level jobs for processes and procedures that must take place in order to keep the warehouse up to date. Application Messaging Layer: this layer is responsible for or transporting info around the enterprise computing network. Also called “middleware”, the AML also involve more than just networking protocols. It can also be used to isolate applications from (op or info) from the exact data format on either end. Further, AML can be used to gather transactions or messages and deliver them to a certain location at a certain time. It is the main transport system of a warehouse. Data Warehouse Layer: The core – where the data being used for mostly informational uses occurs. It can be thought of as a “virtual: or “logical” view of data. On many instances, the data warehouse may not actually involve storing data. In the Physical Data Warehouse, copies or several copies of operational or external data are stored in a format that is easy and flexible to get to. The warehouse may be stored on a client/server or mainframe platforms. Data Staging Layer: The final part of Data Warehousing Architecture. This layer is also called copy management or replication management. But, it includes ALL of the processes required to select, edit, summarize, combine and load warehouse and info access data from operational/external databases.
OLAP vs. OLTP |