| HOME | Project Management Data Warehousing / Mining Software Testing | Technical Writing |
|
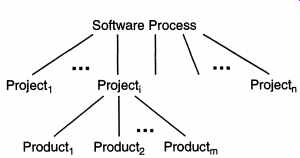
As we saw in the previous section, the concept of process is at the heart of the software engineering approach. According to Webster, the term process means "a particular method of doing something, generally involving a number of steps or operations." In software engineering, the phrase software process refers to the method of developing software. A software process is a set of activities, together with ordering constraints among them, such that if the activities are performed properly and in accordance with the ordering constraints, the desired result is produced. The desired result is, as stated earlier, high-quality software at low cost. Clearly, a process that does not scale up (i.e., cannot handle large software projects) or cannot produce good-quality software (i.e., good-quality software is not the outcome) is not a suitable process. In this section, we will discuss the concept of software processes, the component processes of a software process, and some models that have been proposed. 1. Software Process In an organization whose major business is software development, there are typically many processes simultaneously executing. Many of these do not concern software engineering, though they do impact software development. These could be considered non software-engineering process models. Business process models, social process models, and training models, are all examples of processes that come under this. These processes also affect the software development activity but are beyond the purview of software engineering. The process that deals with the technical and management issues of software development is called a software process. Clearly, many different types of activities need to be performed to develop software. As we have seen earlier, a software development project must have at least development activities and project management activities. All these activities together comprise the software process. As different type of activities are being performed, which are frequently done by different people, it is better to view the software process as consisting of many component processes, each consisting of a certain type of activity. Each of these component processes typically has a different objective, though these processes obviously cooperate with each other to satisfy the overall software engineering objective. In this section we will define the major component processes of a software process and what their objectives are. Before we do that, let us first clearly understand the three important entities that repeatedly occur in software engineering-software processes, software projects, and software products-and their relationship. 1.1 Processes, Projects, and Products A software process, as mentioned earlier, specifies a method of developing soft ware. A software project, on the other hand, is a development project in which a software process is used. And software products are the outcomes of a software project. Each software development project starts with some needs and (hopefully) ends with some software that satisfies those needs. A software process specifies the abstract set of activities that should be performed to go from user needs to final product. The actual act of executing the activities for some specific user needs is a software project. And all the outputs that are produced while the activities are being executed are the products (one of which is the final software). One can view the software process as an abstract type, and each project is done using that process as an instance of this type. In other words, there can be many projects for a process (i.e., many projects can be done using a process), and there can be many products produced in a project. This relationship is shown in FIG. 1. ----------
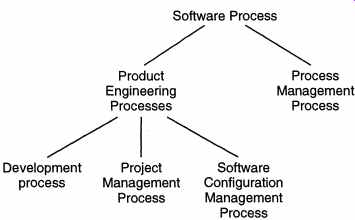
---------- A pertinent question that comes up is if the sequence of activities is provided by the process, what is the difficulty in following it in a project? First, the sequence of activities specified by the process is typically at an abstract level because they have to be usable for a wide range of projects. Hence, "implementing" them in a project is not straightforward. To clarify this, let us take the example of traveling. A process for traveling to a destination will be something like this: Set objectives for the travel (tourism, business, meeting friends, etc.), determine the optimal means of traveling (this will depend on the objective), if driving is best determine what type of vehicle is most desired (car, truck, or camper), get a detailed map to reach the destination, plan details of the trip, get sufficient money, rent the car, etc. If flying to the destination is best, then guide flights, reserve a car at the destination if needed, etc. In a sense, the process provides a "checklist," with an ordering constraint (e.g., renting a car as a first step is suboptimal). If one has to go from New York to Orlando (a specific project), then even with this process, a considerable effort is required to reach Orlando. And this effort is not all passive; one has to be alert and active to achieve this goal (e.g., preparing a map and following the map are not passive or trivial tasks). Overall, the process specifies activities at an abstract level that are not project specific. It is a generic set of activities that does not provide a detailed roadmap for a particular project. The detailed roadmap for a particular project is the project plan that specifies what specific activities to perform for this particular project, when, and how to ensure that the project progresses smoothly. In our travel example, the project plan to go from New York to Orlando will be the detailed marked map showing the route, with other details like plans for night halts, getting gas, and breaks. It should be clear that it is the process that drives a project. A process limits the degrees of freedom for a project by specifying what types of activities must be done and in what order. Further restriction on the degrees of freedom for a particular project are specified by the project plan, which, in itself, is within the boundaries established by the process (i.e., a project plan cannot include performing an activity that is not there in the process). With this, the hope is that one has the "shortest" (or the most efficient) path from the user needs to the software satisfying these needs. As each project is an instance of the process it follows, it is essentially the pro cess that determines the expected outcomes of a project. Due to this, the focus of software engineering is heavily on the process. 1.2 Component Software Processes The three basic type of entities that software engineering deals with-processes, project, and products-require different processes. The major process dealing with products is the development process responsible for producing the desired product (i.e., the software) and other products (e.g., user manual, and requirement specification). The basic goal of this process is to develop a product that will satisfy the customer. A software project is clearly a dynamic entity in which activities are performed, and project management process is needed to properly control this dynamic activity, so that the activities do not take the project astray but all activities are geared toward reaching the project goal. For large projects, project management is perhaps even more important than technical methods for the success of the project. Hence, we can clearly identify that there are two major components in a software process-a development process and a project management process corresponding to the two axes in Figure 2. The development process specifies the development and quality assurance activities that need to be performed, whereas the management process specifies how to plan and control these activities so that project objectives are met. The development process and the project management process both aim at satisfying the cost and quality objectives of the project. However, as we have seen, change and rework in a project occur constantly, and any software project has to deal with the problems of change and rework satisfactorily. As the development processes generally cannot handle change requests at an arbitrary point in time, to handle the inevitable change and rework requests another processes called software configuration control process, is generally used. The objective of this component process is to primarily deal with managing change, so that the cost and quality objectives are met and the integrity of the products is not violated despite these change requests. Overall, for a particular project, to satisfy the objectives and handle the realities of software, at least three major constituent processes are needed: development process, project management process, and configuration control process. (One can think of other processes to~, e.g., training process or business process, but these can be considered minor processes as far as software engineering is considered.) It should be clear that both the project management process and the configuration control process depend on the development process. As the management process aims to control the development process, it clearly depends on the activities in the development process. Though the configuration control process is not as closely tied to the development process as the management process is, what changes to allow and how to process and manage a change depend on the development process, as the effect of the change depends on methods used. For this reason there is some sort of primacy of the development process, which is reflected in the fact that models have generally been proposed for the development processes. The management process, for example, is typically developed after the development process has been adopted. These three constituent processes focus on the projects and the products. In fact, they can be all considered as comprising product engineering processes, as their main objective is to produce the desired product. If the software process can be viewed as a static entity, then these three component processes will suffice. How-ever, a software process itself is a dynamic entity, as it must change to adapt to our increased understanding about software development and availability of newer technologies and tools. Due to this, a process to manage the software process is needed.
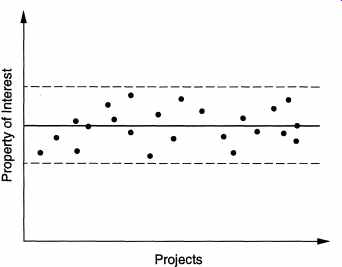
The process management process deals with the software process; its basic objective is to improve the software process. By improvement, we mean that the capability of the process to produce quality goods at low cost is improved. For this, the current software process is studied, frequently by studying the projects that have been done using the project. Based on the analysis of the existing process, various aspects of the development, project management, configuration management, or other minor processes that affect software development are improved, thereby improving the software process. The whole process of understanding the current process, analyzing its properties, determining how to improve, and then affecting the improvement is dealt with by the process management process. The relations hip between these major component processes is shown in FIG. 2. These component processes are distinct not only in the type of activities performed in them, but typically also in the people who perform the activities specified by the process. In a typical project, development activities are performed by programmers, designers, testing personnel, librarians, writers, etc.; the project management process activities are performed by the project management; configuration control process activities are performed by a group generally called the configuration control board; and the process management process activities are performed by a group called the software engineering process group (SEPG). In the rest of this section we will discuss each of these processes further. However, in the rest of the guide we will focus primarily on processes relating to product engineering, as process management is an advanced topic beyond the scope of this guide. The rest of the guide essentially discusses various components of a development process (frequently called methodologies for the particular phase of the development process), and for each component discusses its relationship with the project management process. We will use the term software process to mean product engineering processes, unless specified otherwise. 2. Characteristics of a Software Process Before we discuss the constituent processes of a software process, let us discuss some desirable characteristics of the software process (besides the fact that it should provide effective development, management, and change management support). The fundamental objectives of a process are the same as that of software engineering (after all, the process is the main vehicle of satisfying the software engineering objectives), namely, optimality and scalability. Optimality means that the process should be able to produce high-quality software at low cost, and scalability means that it should also be applicable for large software projects. To achieve these objectives, a process should have some properties. We will discuss some of the important ones in this section. 2.1 Predictability Predictability of a process determines how accurately the outcome of following a process in a project can be predicted before the project is completed. Predictability can be considered a fundamental property of any process. In fact, if a process is not predictable, it is of limited use. Let us see why. We have seen that effective project management is essential for the success of a project, and effective project management revolves around the project plan. A project plan typically contains cost and schedule estimates for the project, along with plans for quality assurance and other activities. Any estimation about a project is based on the properties of the project, and the capability or past experience of the organization. For example, a simple way of estimating cost could be to say, "this project A is very similar to the project B that we did 2 years ago, hence A's cost will be very close to B 's cost." However, even this simple method implies that the process that will be used to develop project A will be same as the process used for project B, and the process is such that following the process the second time will produce similar results as the first time. That is, this assumes that the process is predictable. If it was not predictable, then there is no guarantee that doing a similar project the second time using the process will incur a similar cost. Similar is the situation with quality. The fundamental basis for quality prediction is that quality of the product is determined largely by the process used to develop it. Using this basis, quality of the product of a project can be estimated or predicted by seeing the quality of the products that has been produced in the past by the process being used in the current project. In fact, effective management of quality assurance activities largely depends on the predictability of the process. For example, for effective quality assurance, one method is to estimate what types and quantity of errors will be detected at what stage of the development, and then use to determine if the quality assurance activities are being performed properly. This can only be done if the process is predictable; based on the past experience of such a process one can estimate the distribution of errors for the current project. Otherwise, how can anyone say whether detecting 10 errors per 100 lines of code (LOC) during testing in the current project is "acceptable"? With a predictable process, if the process is such that one expects 10 errors per 100 LOC during testing, this means that the testing of this project was probably done properly. But, if past experience with the process shows that about 20 errors per 100 LOC are detected during testing, then a careful look at the testing of the current project is necessary. It should be clear that if we want to use the past experience to control costs and ensure quality, we must use a process that is predictable. With low predictability, the experience gained through projects is of little value. A predictable process is also said to be under statistical control. A process is under statistical control if following the same process produces similar results. This is shown in FIG. 3; the y-axis represents some property of interest (quality, productivity, etc.), and x-axis represents the projects. The dark line is the expected value of the property for this process. Statistical control implies that most projects will be within abound around the expected value.
Statistical control also implies that the predictions for a process, which are generally based on the past performance of the process, are only probabilistic. If 20 errors per 100 LOC have been detected in the past for a process (which is under statistical control), then it is expected that with a high probability, this is the range of errors that will be detected during testing in future projects. Still, it is possible that in some projects this may not happen. This may happen if the programmer was very good, had a bout of excellence, or the code was easy, etc. Due to this, any data about the current project beyond the range suggested by the process, implies that the data and the project should be carefully examined and allowed to "pass through" only if clear evidence is found that this is a "statistical aberration." It should be clear that if one hopes to consistently develop software of high quality at low cost, it is necessary to have a process that is under statistical control. A predictable process is an essential requirement for ensuring good quality and low cost. Note that this does not mean that one can never produce high-quality software at low cost without following such a process. It is always possible that a set of bright people might do it. However, what this means is that without such a process, such things cannot be repeated. Hence, if one wants quality consistently across many projects, having a predictable process is essential. Because software engineering is interested in general methods that can be used to develop different software, a predictable process forms the backbone of the software engineering methods. 2.2 Support Testability and Maintainability We have already seen that in the life of software the maintenance costs generally exceed the development costs. Clearly, if we want to reduce the overall cost of soft ware or achieve "global" optimality in terms of cost rather than "local" optimality in terms of development cost only, the goal of development should be to reduce the maintenance effort. That is, one of the important objectives of the development project should be to produce software that is easy to maintain. And the process should be such that it ensures this maintainability. Frequently, the software produced is not easily maintainable. This clearly implies that the development process used for developing software frequently does not have maintainability as a clear goal. One possible reason for this is that the developers frequently develop the software, install it, and then hand it over to a different set of people called maintainers. The maintainers frequently don't even belong to the organization that developed the software but rather to the organization that contracted out the development. In such a situation, clearly there is no incentive for the developers to develop maintainable software, as they don't have to put in the effort for maintenance. This situation can only be alleviated if the developers are made responsible for maintenance, at least for a couple of years after the delivery of software. Even in development, coding is frequently given a great degree of importance. We have seen that a process consists of phases, and a process generally includes requirements, design, coding, and testing phases. Of the development cost, an example distribution of effort with the different phases is shown in Table 1. The exact numbers will differ with organization and the nature of the process. However, there are some observations we can make. First is that coding consumes only a small percentage of the development effort. This is against the common naive notion that developing software is largely concerned with writing programs and that programming is the major activity. Another way of determining the effort spent in programming is to study how programmers spend their time in a software organization. A study conducted in Bell Labs to determine how programmers spend their time, as reported in [Fai85], found the distribution shown in Table 2. --------------------------------
TABLE 1. Effort distribution with phases. -----------------
TABLE 2. How programmers spend their time. --------------------------------- This data clearly shows that programming is not the major activity where programmers spend their time. Even if we take away the time spent in "other" activities, the time spent by a programmer writing programs is still less than 25% of the remaining time. It also shows that job communication, which includes meetings, writing memos, discussions, etc., consumes the most time of the programmers. In the study reported by Boehm, it was found that programmers spend less than 20% of their time programming. Both these studies show that writing programs does not consume much of the programmers' time, it is 15 to 25% of the total time spent on projects. These data provide additional validation that coding is not the major activity in software development. The second important observation from the data about effort distribution with phases is that testing consumes the most resources during development. This is, again, contrary to the common practice, which considers testing a side activity that is often not properly planned. Underestimating the testing effort often causes the planners to allocate insufficient resources for testing, which, in turn, results in unreliable software or schedule slippage. Overall, we can say that the goal of the process should not be to reduce the effort of design and coding, but to reduce the cost of testing and maintenance. Both testing and maintenance depend heavily on the design and coding of software, and these costs can be considerably reduced if the software is designed and coded to make testing and maintenance easier. Hence, during the early phases of the development process the prime issues should be "can it be easily tested" and "can it be easily modified." 2.3 Early Defect Removal and Defect Prevention The notion that programming is the central activity during software development is largely due to programming being considered a difficult task and sometimes an "art." Another consequence of this kind of thinking is the belief that errors largely occur during programming, as it is the hardest activity in software development and offers many opportunities for committing errors. It is now clear that errors can occur at any stage during development. An example distribution of error occurrences by phase is:
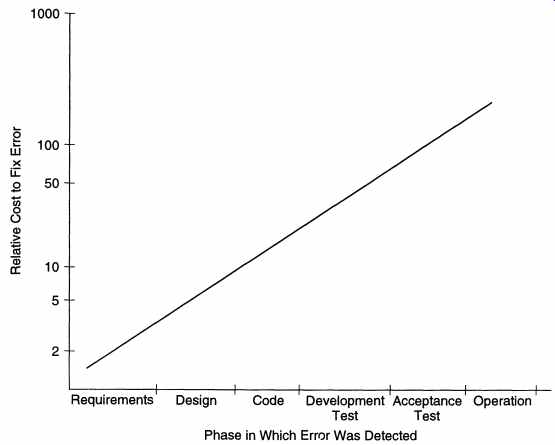
As we can see, errors occur throughout the development process. However, the cost of correcting errors of different phases is not the same and depends on when the error is detected and corrected. The relative cost of correcting requirement errors as a function of where they are detected is shown in FIG. 4. As one would expect, the greater the delay in detecting an error after it occurs, the more expensive it is to correct it. As the figure shows, an error that occurs during the requirements phase, if corrected during acceptance testing, can cost up to 100 times more than correcting the error during the requirements phase itself. The reason for this is fairly obvious. If there is an error in the requirements, then the design and the code will be effected by it. To correct the error after the coding is done would require both the design and the code to be changed, thereby increasing the cost of correction. The main moral of this section is that we should attempt to detect errors that occur in a phase during that phase itself and should not wait until testing to detect errors. This is not often practiced. In reality, sometimes testing is the sole point where errors are detected. Besides the cost factor, reliance on testing as the primary source for error detection, due to the limitations of testing, will also result in unreliable software. Error detection and correction should be a continuous process that is done throughout software development. In terms of the development phases, this means that we should try to verify the output of each phase before starting with the next.
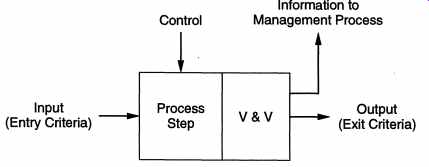
Detecting errors soon after they have been introduced is dearly an objective that should be supported by the process. However, even better is to provide support for defect prevention. It is generally agreed that all the defect removal methods that exist today are limited in their capability and cannot detect all the defects that are introduced. (Why else are there bugs in most software that are released and are then fixed in later versions?) Furthermore, the cost of defect removal is generally high, particularly if they are not detected for a long time. Clearly, then, to reduce the total number of residual defects that exist in a system at the time of delivery and to reduce the cost of defect removal, an obvious approach is to prevent defects from getting introduced. This requires that the process of performing the activities should be such that fewer defects are introduced. The method generally followed to support defect prevention is to use the development process to learn (from previous projects) so that the methods of performing activities can be improved. 2.4 Process Improvement As mentioned earlier, a process is also not a static entity. Improving the quality and reducing the cost of products are fundamental goals of any engineering discipline. In the context of software, as the productivity (and hence the cost of a project) and quality are determined largely by the process, to satisfy the engineering objectives of quality improvement and cost reduction, the software process must be improved. Having process improvement as a basic goal of the software process implies that the software process used is such that it supports its improvement. This requires that there be means for evaluating the existing process and understanding the weak nesses in the process. Only when support for these activities is available can process improvement be undertaken. And, as in any evaluation, it is always preferable to have a quantifiable evaluation rather than a subjective evaluation. Hence, it is important that the process provides data that can be used to evaluate the current process and its weaknesses. Having process improvement as a fundamental objective requires that the soft ware process be a closed-loop process. That is, the process must learn from previous experiences, and each project done using the existing process must feed information back into the process itself, which can then use this information for self-improvement. As stated earlier, this activity is largely done by the process management component of the software process. However, to support this activity, information from various other processes will have to flow to the process management process. In other words, to support this activity, other processes will also have to take an active part. 3. Software Development Process In the software development process we focus on the activities directly related to production of the software, for example, design, coding, and testing. A development process model specifies some activities that, according to the model, should be performed, and the order in which they should be performed. As stated earlier, for cost, quality, and project management reasons, development processes are generally phased. As the development process specifies the major development and quality assurance activities that need to be performed in the project, the development process really forms the core of the software process. The management process is decided based on the development process. Due to the importance of development process, various models have been proposed. In this section we will discuss some of the major models. As processes consist of a sequence of steps, let us first discuss what should be specified for a step. 3.1 A Process Step Specification A production process is a sequence of steps. Each step performs a well-defined activity leading toward the satisfaction of the project goals, with the output of one step forming the input of the next one. Most process models specify the steps that need to be performed and the order in which they need to be performed. However, when implementing a process model, there are some practical issues like when to initiate a step and when to terminate a step that need to be addressed. Here we discuss some of these issues. As we have seen, a process should aim to detect defects in the phase in which they are introduced. This requires that there be some verification and validation (V & V) at the end of each step. (In verification, consistency with the inputs of the phase is checked, while in validation the consistency with the needs of user is checked.) This implies that there is a clearly defined output of a phase, which can be verified by some means and can form input to the next phase (which may be performed by other people). In other words, it is not acceptable to say that the output of a phase is an idea or a thought in the mind of someone; the output must be a formal and tangible entity. Such outputs of a development process, which are not the final output, are frequently called the work products. In software, a work product can be the requirements document, design document, code, prototype, etc. This restriction that the output of each step be some work product that can be verified suggests that the process should have a small number of steps. Having too many steps results in too many work products or documents, each requiring V & V, and can be very expensive. Due to this, at the top level, a development process typically consists of a few steps, each satisfying a clear objective and producing a document used for V & V. How to perform the activity of the particular step or phase is generally not an issue of the development process. This is an issue addressed by methodologies for that activity. We will discuss various methodologies for different activities throughout the guide. As a development process typically contains a sequence of steps, the next issue that comes is when a phase should be initiated and terminated. This is frequently done by specifying the entry criteria and exit criteria for a phase. The entry criteria of a phase specifies the conditions that the input to the phase should satisfy in order to initiate the activities of that phase. The output criteria specifies the conditions that the work product of this phase should satisfy in order to terminate the activities of the phase. The entry and exit criteria specify constraints of when to start and stop an activity. It should be clear that the entry criteria of a phase should be consistent with the exit criteria of the previous phase. The entry and exit criteria for a phase in a process depend largely on the implementation of the process. For example, for the same process, one organization may have the entry criteria for the design phase as "requirements document signed by the client" and another may have "no more than X errors detected per page in the requirement review." As each phase ends with some V & V activity, a common exit criteria for a phase is "V & V of the phase completed satisfactorily," where satisfactorily is defined by the organization based on the objectives of the project and its experience in using the process. The specification of a step with its input, output, and entry and exit criteria is shown in FIG. 5. ------------------
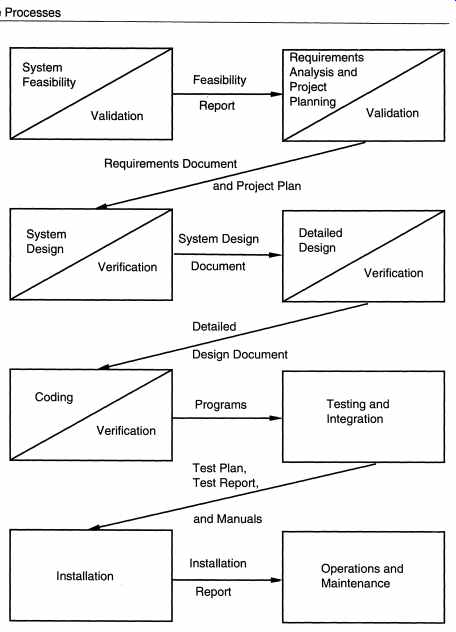
Input (Entry Criteria) Control Process Step Information to Management Process V&V Output (Exit Criteria) ------------------- Besides the entry and exit criteria for the input and output, a development step needs to produce some information for the management process. We know that the basic goal of the management process is to control the development process. For controlling a process, the management process needs to have precise knowledge about the development process activities. As the management process is executed by a logically separate group of people, the information about the development process must flow from the development process to the management process. This requires that a step produce some information for the management process. The nature of this information is specified by the management process, based on its needs. (Note the tight coupling of the management process with the development process.) This information (and other such information from previous steps) is used by the management process to exert control on the development process. The flow of information from a step and exercise of control is also shown in FIG. 5. Generally, the information flow from a step is in the form of summary reports describing the amount of resources spent in the phase, schedule information, errors found in the V & V activities, etc. This type of information flow at defined points in the development process makes it possible for the project management (i.e., the people executing the management process) to get precise information about the development process, without being directly involved in the development process or without going through the details of all activities of a phase. It should be dear that the entry and exit criteria and the nature of information flow depends on how the process is implemented in an organization and on the project. Consequently, process models typically do not specify these. However, they must be specified by an organization, if it wishes to adopt a process model for software development. 3.2 Waterfall Model We now discuss some of the common process models that have been proposed. The simplest process model is the waterfall model, which states that the phases are organized in a linear order. There are various variations of the waterfall model depending on the nature of activities and the flow of control between them. In a typical model, a project begins with feasibility analysis. On successfully demonstrating the feasibility of a project, the requirements analysis and project planning begins. The design starts after the requirements analysis is complete, and coding begins after the design is complete. Once the programming is completed, the code is integrated and testing is done. On successful completion of testing, the system is installed. After this, the regular operation and maintenance of the system takes place. The model is shown in FIG. 6. In this guide, we will only discuss the activities related to the development of soft ware. Thus, we will only discuss phases from requirements analysis to testing. The requirements analysis phase is mentioned as "analysis and planning." Planning is a critical activity in software development. A good plan is based on the requirements of the system and should be done before later phases begin. However, in practice, detailed requirements are not necessary for planning. Consequently, planning usually overlaps with the requirements analysis, and a plan is ready before the later phases begin. This plan is an additional input to all the later phases. With the waterfall model, the sequence of activities performed in a software development project is: requirement analysis, project planning, system design, detailed design, coding and unit testing, system integration and testing. This is the order the different phases will be discussed in this guide, keeping the sequence as close as possible to the sequence in which the activities are performed. Linear ordering of activities has some important consequences. First, to clearly identify the end of a phase and the beginning of the next, some certification mechanism has to be employed at the end of each phase. This is usually done by some verification and validation means that will ensure that the output of a phase is consistent with its input (which is the output of the previous phase), and that the output of the phase is consistent with the overall requirements of the system. The consequence of the need for certification is that each phase must have some defined output that can be evaluated and certified. That is, when the activities of a phase are completed, there should be some product that is produced by that phase. And the goal of a phase is to produce this product. The outputs of the earlier phases are often called work products (or intermediate products) and are usually in the form of documents like the requirements document or design document. For the coding phase, the output is the code. From this point of view, the output of a software project is not just the final program along with the user documentation, but also the requirements document, design document, project plan, test plan, and test results. Let us now consider the rationale behind the waterfall model. There are two basic assumptions for justifying the linear ordering of phases in the manner proposed by the waterfall model: --------------------
System Feasibility System Design Coding Validation Verification; Verification Installation Requirements Analysis and the Feasibility Project Report Planning System Design Document Programs Installation Report Detailed Design Testing and Integration Operations and Maintenance -------------------- 1. For a successful project resulting in a successful product, all phases listed in the waterfall model must be performed anyway. 2. Any different ordering of the phases will result in a less successful software product. A successful software product is one that satisfies all the objectives of the development project. These objectives include satisfying the requirements and performing the development within time and cost constraints. Generally, for any reasonable size project, all the phases listed in the model must be performed explicitly and formally. Informally performing the phases will work only for very small projects. The second reason is the one that is now under debate. For many projects, the linear ordering of these phases is clearly the optimum way to organize these activities. However, some argue that for many projects this ordering of activities is unfeasible or suboptimum. We will discuss some of these ideas shortly. Still, the waterfall model is conceptually the simplest process model for software development that has been used most often. Project Outputs in Waterfall Model As we have seen, the output of a project employing the waterfall model is not just the final program along and documentation to use it. There are a number of intermediate outputs that must be produced to produce a successful product. Though the set of documents that should be produced in a project is dependent on how the process is implemented, the following is a set of documents that generally forms the minimum set that should be produced in each project: • Requirements document • Project plan • System design document • Detailed design document • Test plan and test reports • Final code • Software manuals (e.g., user, installation, etc.) • Review reports Except for the last one, these are the outputs of the phases, and they have been briefly discussed. To certify an output product of a phase before the next phase begins, reviews are often held. Reviews are necessary, especially for the requirements and design phases, because other certification means are frequently not available. Reviews are formal meetings to uncover deficiencies in a product and will be discussed in more detail later. The review reports are the outcome of these reviews. Limitations of the Waterfall Model The waterfall model, although widely used, has received some criticism. Here we list some of these criticisms: 1. The waterfall model assumes that the requirements of a system can be frozen (i.e. baselined) before the design begins. This is possible for systems designed to automate an existing manual system. But for new systems, determining the requirements is difficult as the user does not even know the requirements. Hence, having unchanging requirements is unrealistic for such projects. 2. Freezing the requirements usually requires choosing the hardware (because it forms apart of the requirements specification). A large project might take a few years to complete. If the hardware is selected early, then due to the speed at which hardware technology is changing, it is likely that the final software will use a hardware technology on the verge of becoming obsolete. This is clearly not desirable for such expensive software systems. 3. The waterfall model stipulates that the requirements be completely specified before the rest of the development can proceed. In some situations it might be desirable to first develop a part of the system completely and then later enhance the system in phases. This is often done for software products that are developed not necessarily for a client (where the client plays an important role in requirements specification), but for general marketing, in which case the requirements are likely to be determined largely by the developers themselves. 4. It is a document driven process that requires formal documents at the end of each phase. This approach tends to make the process documentation-heavy and is not suitable for many applications, particularly interactive applications, where developing elaborate documentation of the user interfaces is not feasible. Also, if the development is done using fourth-generation languages or modem development tools, developing elaborate specifications before implementation is sometimes unnecessary. Despite these limitations, the waterfall model is the most widely used process model. It is well suited for routine types of projects where the requirements are well understood. That is, if the developing organization is quite familiar with the problem domain and the requirements for the software are quite clear, the waterfall model works well.
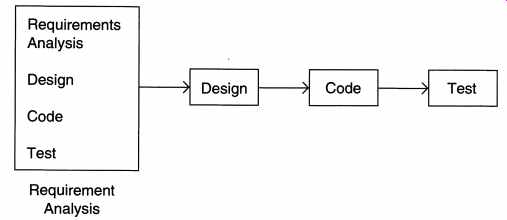
3.3 Prototyping The goal of a prototyping-based development process is to counter the first two limitations of the waterfall model. The basic idea here is that instead of freezing the requirements before any design or coding can proceed, a throwaway prototype is built to help understand the requirements. This prototype is developed based on the currently known requirements. Development of the prototype obviously undergoes design, coding, and testing, but each of these phases is not done very formally or thoroughly. By using this prototype, the client can get an actual feel of the system, because the interactions with the prototype can enable the client to better understand the requirements of the desired system. This results in more stable requirements that change less frequently. Prototyping is an attractive idea for complicated and large systems for which there is no manual process or existing system to help determine the requirements. In such situations, letting the client "play" with the prototype provides invaluable and intangible inputs that help determine the requirements for the system. It is also an effective method of demonstrating the feasibility of a certain approach. This might be needed for novel systems, where it is not clear that constrains can be met or that algorithms can be developed to implement the requirements. In both situations, the risks associated with the projects are being reduced through the use of prototyping. The process model of the prototyping approach is shown in FIG. 7. A development process using throwaway prototyping typically proceeds as follows. The development of the prototype typically starts when the preliminary version of the requirements specification document has been developed. At this stage, there is a reasonable understanding of the system and its needs and of which needs are unclear or likely to change. After the prototype has been developed, the end users and clients are given an opportunity to use the prototype and play with it. Based on their experience, they provide feedback to the developers regarding the prototype: what is correct, what needs to be modified, what is missing, what is not needed, etc. Based on the feedback, the prototype is modified to incorporate some of the suggested changes that can be done easily, and then the users and the clients are again allowed to use the system. This cycle repeats until, in the judgment of the prototypers and analysts, the benefit from further changing the system and obtaining feedback is outweighed by the cost and time involved in making the changes and obtaining the feedback. Based on the feedback, the initial requirements are modified to produce the final requirements specification, which is then used to develop the production quality system. For prototyping for the purposes of requirement analysis to be feasible, its cost must be kept low. Consequently, only those features are included in the prototype that will have a valuable return from the user experience. Exception handling, recovery, and conformance to some standards and formats are typically not included in prototypes. In prototyping, as the prototype is to be discarded, there is no point in implementing those parts of the requirements that are already well understood. Hence, the focus of the development is to include those features that are not properly understood. And the development approach is "quick and dirty" with the focus on quick development rather than quality. Because the prototype is to be thrown away, only minimal documentation needs to be produced during prototyping. For example, design documents, a test plan, and a test case specification are not needed during the development of the prototype. Another important cost-cutting measure is to reduce testing. Because testing consumes a major part of development expenditure during regular software development, this has a considerable impact in reducing costs. By using these type of cost-cutting methods, it is possible to keep the cost of the prototype less than a few percent of the total development cost. Prototyping is often not used, as it is feared that development costs may become large. However, in some situations, the cost of software development without prototyping may be more than with prototyping. There are two major reasons for this. First, the experience of developing the prototype might reduce the cost of the later phases when the actual software development is done. Secondly, in many projects the requirements are constantly changing, particularly when development takes a long time. We saw earlier that changes in requirements at a late stage during development substantially increase the cost of the project. By elongating the requirements analysis phase (prototype development does take time), the requirements are "frozen" at a later time, by which time they are likely to be more developed and, consequently, more stable. In addition, because the client and users get experience with the system, it is more likely that the requirements specified after the prototype will be closer to the actual requirements. This again will lead to fewer changes in the requirements at a later time. Hence, the costs incurred due to changes in the requirements may be substantially reduced by prototyping. Hence, the cost of the development after the prototype can be substantially less than the cost without prototyping; we have already seen how the cost of developing the prototype itself can be reduced. Prototyping is catching on. It is well suited for projects where requirements are hard to determine and the confidence in obtained requirements is low. In such projects, a waterfall model will have to freeze the requirements in order for the development to continue, even when the requirements are not stable. This leads to requirement changes and associated rework while the development is going on. Requirements frozen after experience with the prototype are likely to be more stable. Overall, in projects where requirements are not properly understood in the beginning, using the prototyping process model can be the most effective method for developing the software. It is an excellent technique for reducing some types of risks associated with a project. We will further discuss prototyping when we discuss requirements specification and risk management. ----------------------------
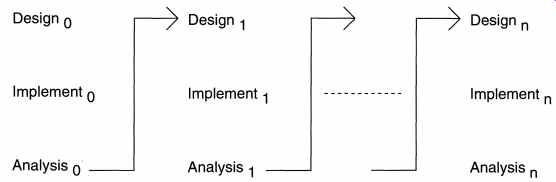
------------------------------- 3.4 Iterative Enhancement The iterative enhancement model counters the third limitation of the waterfall model and tries to combine the benefits of both prototyping and the waterfall model. The basic idea is that the software should be developed in increments, each increment adding some functional capability to the system until the full system is implemented. At each step, extensions and design modifications can be made. An advantage of this approach is that it can result in better testing because testing each increment is likely to be easier than testing the entire system as in the water fall model. Furthermore, as in prototyping, the increments provide feedback to the client that is useful for determining the final requirements of the system. In the first step of this model, a simple initial implementation is done for a subset of the overall problem. This subset is one that contains some of the key aspects of the problem that are easy to understand and implement and which form a useful and usable system. A project controllist is created that contains, in order, all the tasks that must be performed to obtain the final implementation. This project controllist gives an idea of how far the project is at any given step from the final system. Each step consists of removing the next task from the list, designing the implementation for the selected task, coding and testing the implementation, performing an analysis of the partial system obtained after this step, and updating the list as a result of the analysis. These three phases are called the design phase, implementation phase, and analysis phase. The process is iterated until the project controllist is empty, at which time the final implementation of the system will be available. The iterative enhancement process model is shown in FIG. 8. The project control list guides the iteration steps and keeps track of all tasks that must be done. Based on the analysis, one of the tasks in the list can include redesign of defective components or redesign of the entire system. However, redesign of the system will generally occur only in the initial steps. In the later steps, the design would have stabilized and there is less chance of redesign. Each entry in the list is a task that should be performed in one step of the iterative enhancement process and should be simple enough to be completely understood. Selecting tasks in this manner will minimize the chances of error and reduce the redesign work. The design and implementation phases of each step can be performed in a top-down manner or by using some other technique. One effective use of this type of model is for product development, in which the developers themselves provide the specifications and therefore have a lot of control on what specifications go in the system and what stay out. In fact, most products undergo this type of development process. First, aversion is released that contains some capability. Based on the feedback from users and experience with this version, a list of additional desirable features and capabilities is generated. These features form the basis of enhancement of the software, and are included in the next version. In other words, the first version contains some core capability. And then more features are added to later versions. However, in a customized software development, where the client has to essentially provide and approve the specifications, it is not always clear how this process can be applied. Another practical problem with this type of development project comes in generating the business contract-how will the cost of additional features be determined and negotiated, particularly because the client organization is likely to be tied to the original vendor who developed the first version. Overall, in these types of projects, this process model can be useful if the "core" of the application to be developed is well understood and the "increments" can be easily defined and negotiated. In client-oriented projects, this process has the major advantage that the client's organization does not have to pay for the entire software together; it can get the main part of the software developed and perform cost-benefit analysis for it before enhancing the software with more capabilities. ----
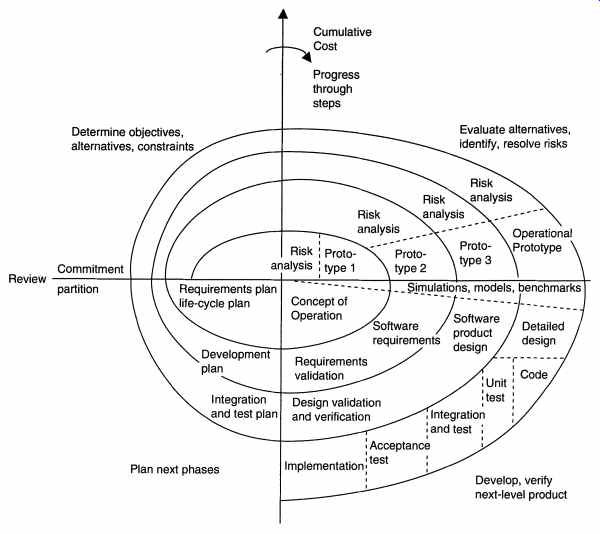
Determine objectives, alternatives, constraints Cumulative Cost Progress through steps Risk , Risk : Prototype 1- - Commitment analysis : Review - partition Integration and test plan Plan next phases Concept 01 Operation Requirements validation Design validation and verification, Integration and test: Acceptance Implementation! test: Develop, verify next-level product --------------------- 3.5 The Spiral Model This is a recent model that has been proposed by Boehm. As the name suggests, the activities in this model can be organized like a spiral that has many cycles. The radial dimension represents the cumulative cost incurred in accomplishing the steps done so far, and the angular dimension represents the progress made in completing each cycle of the spiral. The model is shown in FIG. 9. Each cycle in the spiral begins with the identification of objectives for that cycle, the different alternatives that are possible for achieving the objectives, and the constraints that exist. This is the first quadrant of the cycle (upper-left quadrant). The next step in the cycle is to evaluate these different alternatives based on the objectives and constraints. The focus of evaluation in this step is based on the risk perception for the project. Risks reflect the chances that some of the objectives of the project may not be met. Risk management will be discussed in more detail later in the guide. The next step is to develop strategies that resolve the uncertainties and risks. This step may involve activities such as benchmarking, simulation, and prototyping. Next, the software is developed, keeping in mind the risks. Finally the next stage is planned. The development step depends on the remaining risks. For example, if performance or user-interface risks are considered more important than the program development risks, the next step may be an evolutionary development that involves developing a more detailed prototype for resolving the risks. On the other hand, if the program development risks dominate and the previous prototypes have re solved all the user-interface and performance risks, the next step will follow the basic waterfall approach. The risk-driven nature of the spiral model allows it to accommodate any mixture of a specification-oriented, prototype-oriented, simulation-oriented, or some other type of approach. An important feature of the model is that each cycle of the spiral is completed by a review that covers all the products developed during that cycle, including plans for the next cycle. The spiral model works for development as well as enhancement projects. In a typical application of the spiral model, one might start with an extra round zero, in which the feasibility of the basic project objectives is studied. These project objectives may or may not lead to a development/enhancement project. Such high level objectives include increasing the efficiency of code generation of a compiler, producing a new full-screen text editor and developing an environment for improving productivity. The alternatives considered in this round are also typically very high-level, such as whether the organization should go for in-house development, or contract it out, or buy an existing product. In round one, a concept of operation might be developed. The objectives are stated more precisely and quantitatively and the cost and other constraints are defined precisely. The risks here are typically whether or not the goals can be met within the constraints. The plan for the next phase will be developed, which will involve defining separate activities for the project. In round two the top-level requirements are developed. In succeeding rounds the actual development may be done. This is a relatively new model; it can encompass different development strategies. In addition to the development activities, it incorporates some of the management and planning activities into the model. For high-risk projects this might be a preferred model. |