AMAZON multi-meters discounts AMAZON oscilloscope discounts
1. Corporate Policy for Reliability
A really effective reliability function can exist only in an organization where the achievement of high reliability is recognized as part of the corporate strategy and is given top management attention. If these conditions are not fulfilled, and if it receives only lip service, reliability effort will be cut back whenever cost or time pressures arise. Reliability staff will suffer low morale and won’t be accepted as part of project teams.
Therefore, quality and reliability awareness and direction must start at the top and must permeate all functions and levels where reliability can be affected.
Several factors of modern industrial business make such high level awareness essential. The high costs of repairs under warranty, and of those borne by the user, even for relatively simple items such as domestic electronic and electrical equipment, make reliability a high value property. Other less easily quantifiable effects of reliability, such as customer goodwill and product reputation, and the relative reliability of competing products, are also important in determining market penetration and retention.
2. Integrated Reliability Programs
The reliability effort should always be treated as an integral part of the product development and not as a parallel activity unresponsive to the rest of the development program. This is the major justification for placing responsibility for reliability with the project manager. While specialist reliability services and support can be provided from a central department in a matrix management structure, the responsibility for reliability achievement must not be taken away from the project manager, who is the only person who can ensure that the right balance is struck in allocating resources and time between the various competing aspects of product development.
The elements of a comprehensive and integrated reliability program are shown, related to the overall development, production and in-service program, in FIG. 1 and FIG. 2. These show the continuous feedback of information, so that design iteration can be most effective. Most of the design for reliability (DfR) tools and activities ( Section 7) feature in the FIG. 1 flow.
====
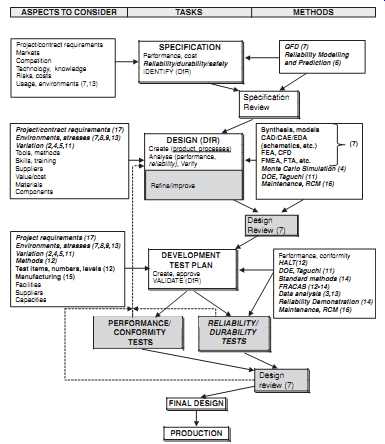
FIG. 1 Reliability Program Flow (design/development).
ASPECTS TO CONSIDER TASKS METHODS SPECIFICATION Performance, cost Reliability/durability/safety IDENTIFY (DfR) Project/contract requirements Markets Competition Technology, knowledge Risks, costs Usage, environments (7,13) QFD (7) Reliability Modeling and Prediction (6) Specification Review DESIGN (DfR) Create (product, processes) Analyze (performance, reliability), Verify Synthesis, models CAD/CAE/EDA (schematics, etc.) FEA, CFD FMEA, FTA, etc.
Monte Carlo Simulation (4) DOE, Taguchi (11) Maintenance, RCM (16) Project/contract requirements (17) Environments, stresses (7,8,9,13) Variation (2,4,5,11) Tools, methods Skills, training Suppliers Value/cost Materials Components (7) Design Review (7) DEVELOPMENT TEST PLAN Create, approve VALIDATE (DfR) Project requirements (17) Environments, stresses (7,8,9,13) Variation (2,4,5,11) Methods (12) Test items, numbers, levels (12) Manufacturing (15) Facilities Suppliers Capacities Performance, conformity HALT(12) DOE, Taguchi (11) Standard methods (14) FRACAS (12-14) Data analysis (3,13) Reliability Demonstration (14) Maintenance, RCM (16) PERFORMANCE/ CONFORMITY TESTS RELIABILITY/ DURABILITY TESTS Design review (7) FINAL DESIGN PRODUCTION Refine/improve
Notes:
1. Items in italics are reliability specific aspects.
2. Figures in brackets indicate relevant sections.
3. Shaded boxes indicate processes that are usually iterative.
4. Dotted lines indicate data feedback (FRACAS).
====
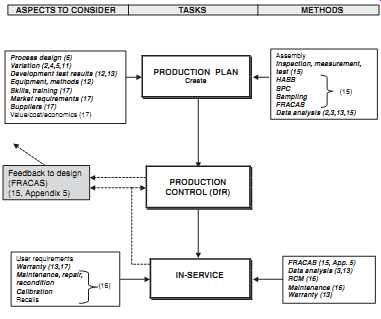
FIG. 2 Reliability Program Flow (production, in-service).
ASPECTS TO CONSIDER TASKS METHODS Process design (6) Variation (2,4,5,11) Development test results (12,13) Equipment, methods (12) Skills, training (17) Market requirements (17) Suppliers (17) Value/cost/economics (17) PRODUCTION PLAN Create Assembly Inspection, measurement, test (15) HASS SPC Sampling FRACAS Data analysis (2,3,13,15) (15) PRODUCTION CONTROL (DfR) IN-SERVICE User requirements Warranty (13,17) Maintenance, repair, recondition Calibration Recalls FRACAS (15, App. 5) Data analysis (3,13) RCM (16) Maintenance (16) Warranty (13) Feedback to design (FRACAS) (15, Sub-section 5) (16)
Notes:
1. Items in italics directly influence reliability.
2. Figures in brackets indicate relevant sections.
3. Shaded boxes indicate processes that are usually iterative.
4. Dotted lines indicate data feedback (FRACAS).
====
Since production quality will affect reliability, quality control is an integral part of the reliability program.
Quality control cannot make up for design shortfalls, but poor quality can negate much of the reliability effort. The quality control effort must be responsive to the reliability requirement and must not be directed only at reducing production costs and the passing of a final test or inspection. Quality control can be made to contribute most effectively to the reliability effort if:
- Quality procedures, such as test and inspection criteria, are related to factors which can affect reliability, and not only to form and function. Examples are tolerances, inspection for flaws which can cause weakening, and the need for adequate screening when appropriate.
- Quality control test and inspection data are integrated with the other reliability data.
- Quality control personnel are trained to recognize the relevance of their work to reliability, and trained and motivated to contribute.
An integrated reliability program must be disciplined. Whilst creative work such as design is usually most effective when not constrained by too many rules and guidelines, the reliability (and quality) effort must be tightly controlled and supported by mandatory procedures. The disciplines of design analysis, test, reporting, failure analysis and corrective action must be strictly imposed, since any relaxation can result in a reduction of reliability, without any reduction in the cost of the program. There will always be pressure to relax the severity of design analyses or to classify a failure as non-relevant if doubt exists, but this must be resisted. The most effective way to ensure this is to have the agreed reliability program activities written down as mandatory procedures, with defined responsibilities for completing and reporting all tasks, and to check by audit and during program reviews that they have been carried out. More material on integrating reliability programs can be found in Silverman (2010).
3 Reliability and Costs
Achieving high reliability is expensive, particularly when the product is complex or involves relatively untried technology. The techniques described in earlier sections require the resources of trained engineers, management time, test equipment and products for testing, and it often appears difficult to justify the necessary expenditure in the quest for an inexact quantity such as reliability. It can be tempting to trust to good basic design and production and to dispense with specific reliability effort, or to provide just sufficient effort to placate a customer who insists upon a visible program without interfering with the 'real' development activity. However, experience points to the fact that all well-managed reliability efforts pay off.
3.1 Costs of Reliability
There are usually practical limits to how much can be spent on reliability during a development program.
However, the authors are unaware of any program in which experience indicated that too much effort was devoted to reliability or that the law of diminishing returns was observed to be operating to a degree which indicated that the program was saturated. This is mainly due to the fact that nearly every failure mode experienced in service is worth discovering and correcting during development, owing to the very large cost disparity between corrective action taken during development and similar action (or the cost of living with the failure mode) once the equipment is in service. The earlier in a development program that the failure mode is identified and corrected the cheaper it will be, and so the reliability effort must be instituted at the outset and as many failure modes as possible eliminated during the early analysis, review and test phases. Likewise, it’s nearly always less costly to correct causes of production defects than to live with the consequences in terms of production costs and unreliability.
It’s dangerous to generalize about the cost of achieving a given reliability value, or of the effect on reliability of stated levels of expenditure on reliability program activities. Some texts show a relationship as in Figure 1.7 ( Section 1) with the lowest total cost (life cycle cost - LCC) indicating the 'optimum reliability' (or quality) point. However, this can be a misleading picture unless all cost factors contributing to the reliability (and unreliability) are accounted for. The direct failure costs can usually be estimated fairly accurately, related to assumed reliability levels and yields of production processes, but the cost of achieving these levels is much more difficult to forecast. There are different models accounting for the cost of reliability.
For example Kleyner and Sandborn (2008) propose a comprehensive life cycle cost model accounting for the various aspects of achieving and demonstrating reliability as well as the consequent warranty costs. As described above, the relationship is more likely to be a decreasing one, so that the optimum quality and reliability is in fact closer to 100%.
Several standard references on quality management suggest considering costs under three headings, so that they can be identified, measured and controlled. These quality costs are the costs of all activities specifically directed at reliability and quality control, and the costs of failure. Quality costs are usually considered in three categories:
- Prevention costs.
- Appraisal costs.
- Failure costs.
Prevention costs are those related to activities which prevent failures occurring. These include reliability efforts, quality control of bought-in components and materials, training and management.
Appraisal costs are those related to test and measurement, process control and quality audit.
Failure costs are the actual costs of failure. Internal failure costs are those incurred during manufacture.
These cover scrap and rework costs (including costs of related work in progress, space requirements for scrap and rework, associated documentation, and related overheads). Failure costs also include external or post-delivery failure costs, such as warranty costs; these are the costs of unreliability.
Obviously it’s necessary to minimize the sum of quality and reliability costs over a suitably long period.
Therefore the immediate costs of prevention and appraisal must be related to the anticipated effects on failure costs, which might be affected over several years. Investment analysis related to quality and reliability is an uncertain business, because of the impossibility of accurately predicting and quantifying the results. Therefore the analysis should be performed using a range of assumptions to determine the sensitivity of the results to assumed effects, such as the yield at test stages and reliability in service.
For example, two similar products, developed with similar budgets, may have markedly different reliabilities, due to differences in quality control in production, differences in the quality of the initial design or differences in the way the reliability aspects of the development program were managed. It’s even harder to say by how much a particular reliability activity will affect reliability. $ 20 000 spent on FMECA might make a large or a negligible difference to achieved reliability, depending upon whether the failure modes uncovered would have manifested themselves and been corrected during the development phase, or the extent to which the initial design was free of shortcomings.
The value gained from a reliability program must, to a large extent, be a subjective judgment based upon experience and related to the way the program is managed. The reliability program will usually be constrained by the resources which can be usefully applied within the development time-scale. Allocation of resources to reliability program activities should be based upon an assessment of the risks. For a complex new design, design analysis must be thorough and searching, and performed early in the program. For a relatively simple adaptation of an existing product, less emphasis may be placed on analysis. In both cases the test program should be related to the reliability requirement, the risks assessed in achieving it and the costs of non-achievement. The two most important features of the program are:
- The statement of the reliability aim in such a way that it’s understood, feasible, mandatory and demonstrable.
- Dedicated, integrated management of the program.
Provided these two features are present, the exact balance of resources between activities won’t be critical, and will also depend upon the type of product. A strong test-analyze-fix program can make up for deficiencies in design analysis, albeit at higher cost; an excellent design team, well controlled and supported by good design rules, can reduce the need for testing. The reliability program for an electronic equipment won’t be the same as for a power station. As a general rule, all the reliability program activities described in this guide are worth applying insofar as they are appropriate to the product, and the earlier in the program they can be applied the more cost-effective they are likely to prove.
In a well-integrated design, development and production effort, with all contributing to the achievement of high quality and reliability, and supported by effective management and training, it’s not possible to isolate the costs of reliability and quality effort. The most realistic and effective approach is to consider all such effort as investments to enhance product performance and excellence, and not to try to classify or analyze them as though they were burdens.
3.2 Costs of Unreliability
The costs of unreliability in service should be evaluated early in the development phase, so that the effort on reliability can be justified and requirements can be set, related to expected costs. The analysis of unreliability costs takes different forms, depending on the type of development program and how the product is maintained. The example below illustrates a typical situation.
Ex. 1
A commercial electronic communication system is to be developed as a risk venture. The product will be sold outright, with a two year parts and labor warranty. Outline the LCC analysis approach and comment on the support policy options.
The analysis must take account of direct and indirect costs. The direct costs can be related directly to failure rate (or removal rate, which is likely to be higher).
The direct costs are:
1. Warranty repair costs.
The annual warranty repair cost will be:
(Number of warranted units in use) × (annual call rate per unit) × (cost per call).
The number of warranted units will be obtained from market projections. The call rate will be related to MTBF and expected utilization.
2. Spares production and inventory costs for warranty support.
Spares costs: to be determined by analysis (e.g. Poisson model, simulation) using inputs of call rate, proportion of calls requiring spares, spares costs, probability levels of having spares in stock, repair time to have spares back in stock, repair and stockholding costs.
3. Net of profit s on post-warranty repairs and spares.
Annual profit on post-warranty spares and repairs: analysis to be similar to warranty costs analysis, but related to post-warranty equipment utilization.
Indirect costs (not directly related to failure or removal rate):
1. Service organization (training manuals, overheads). (Warranty period contribution).
2. Product reputation.
These costs cannot be derived directly. A service organization will be required in any case and its performance will affect the product's reputation. However, a part of its costs will be related to servicing the warranty. A parametric estimate should be made under these headings, For example:
Service organization: 50% of annual warranty cost in first two years, 25% thereafter.
Product reputation: agreed function of call rate.
Since these costs will accrue at different rates during the years following launch, they must all be evaluated for, say, the first ?ve years. The unreliability costs progression should then be plotted ( FIG. 3) to show the relationship between cost and reliability.
The net present values of unreliability cost should then be used as the basis for planning the expenditure on the reliability program.
This situation would be worth analyzing from the point of view of what support policy might show the lowest cost for varying call rates. For example, a very low call rate might make a 'direct exchange, no repair' policy cost-effective, or might make a longer warranty period worth considering, to enhance the product's reputation. Direct exchange would result in service department savings, but a higher spares cost.
The example given above involves very simple analysis and simplifying assumptions. A Monte Carlo simulation ( Section 4) would be a more suitable approach if we needed to consider more complex dynamic effects, such as distributed repair times and costs, multi-echelon repair and progressive increase in units at risk. However, simple analysis is often sufficient to indicate the magnitude of costs, and in many cases this is all that is needed, as the input variables in logistics analysis are usually somewhat imprecise, particularly failure (removal) rate values. Simple analysis is adequate if relatively gross decisions are required. However, if it’s necessary to attempt to make more precise judgments or to perform sensitivity analyses, then more powerful methods such as simulation should be considered.
FIG. 3 Reliability cost progression ( Ex. 1).
There are of course other costs which can be incurred as a result of a product's unreliability. Some of these are hard to quantify, such as goodwill and market share, though these can be very large in a competitive situation and where consumer organizations are quick to publicize failure. In extreme cases unreliability can lead to litigation, especially if damage or injury results. An unreliability cost often overlooked is that due to failures in production due to unreliable features of the design. A reliable product will usually be cheaper to manufacture, and the production quality cost monitoring system should be able to highlight those costs which are due to design shortfalls.
4 Safety and Product Liability
Product liability legislation in the United States, Europe and in other countries adds a new dimension to the importance of eliminating safety-related failure modes, as well as to the total quality assurance approach in product development and manufacture. Before product liability (PL), the law relating to risks in using a product was based upon the principle of caveat emptor ('let the buyer beware'). PL introduced caveat venditor ('let the supplier beware'). PL makes the manufacturer of a product liable for injury or death sustained as a result of failure of his product. A designer can now be held liable for a failure of his design, even if the product is old and the user did not operate or maintain it correctly. Claims for death or injury in many product liability cases can only be defended successfully if the producer can demonstrate that he has taken all practical steps towards identifying and eliminating the risk, and that the injury was entirely unrelated to failure or to inadequate design or manufacture. Since these risks may extend over ten years or even indefinitely, depending upon the law in the country concerned, long-term reliability of safety-related features becomes a critical requirement. The size of the claims, liability being unlimited in the United States, necessitates top management involvement in minimizing these risks, by ensuring that the organization and resources are provided to manage and execute the quality and reliability tasks which will ensure reasonable protection. PL insurance is a business area for the insurance companies, who naturally expect to see a suitable reliability and safety program being operated by the manufacturers they insure.
Abbot and Tyler (1997) provide an overview of this topic.
5. Standards for Reliability, Quality and Safety
Reliability program standard requirements have been issued by several large agencies which place development contracts on industry. The best known of these was US MIL-STD-785 - Reliability Programs for Systems and Equipments, Development and Production which covers all development programs for the US Department of Defense. MIL-STD-785 was supported by other military standards, handbooks and specifications, and these have been referenced in earlier sections. This guide has referred mainly to US military documents, since in many cases they are the most highly developed and best known. However, in 1995 the US Department of Defense cancelled most military standards and specifications, including MIL-STD-785, and downgraded others to handbooks (HDBK) for guidance only. Military suppliers are now required to apply 'best industry practices', rather than comply with mandatory standards.
In the United Kingdom, Defense Standards 00-40 and 00-41 cover reliability program management and methods for defense equipment, and BS 5760 has been published for commercial use, and can be referenced by any organization in developing contracts. ARMP-1 is the NATO standard on reliability and maintainability.
Some large agencies such as NASA, major utilities and corporations issue their own reliability standards.
International standards have also been issued, and some of these are described below.
These official standards generally (but not all) tend to over-emphasize documentation, quantitative analysis, and formal test. They don’t reflect the integrated approach described in this guide and used by many modern engineering companies. They suffer from slow response to new ideas. Therefore they are not much used outside the defense and related industries. However, it’s necessary for people involved in a reliability program, whether from the customer or supplier side, to be familiar with the appropriate standards.
5.1 ISO/IEC60300 (Dependability)
ISO/IEC60300 is the international standard for 'dependability', which is defined as covering reliability, maintainability and safety. It describes management and methods related to these aspects of product design and development. The methods covered include reliability prediction, design analysis, maintenance and support, life cycle costing, data collection, reliability demonstration tests, and mathematical/statistical techniques; most of these are described in separate standards within the ISO/IEC60000 series. Manufacturing quality aspects are not included in this standard. For more on IEC standards see Barringer (2011).
ISO/IEC60300 has not, so far, been made the subject of audits and registration in the way that ISO9000 has (see next section).
5.2 ISO9000 (Quality Systems)
The international standard for quality systems, IS09000, has been developed to provide a framework for assessing the quality management system which an organization operates in relation to the goods or services provided. The concept was developed from the US Military Standard for quality management, MIL-Q-9858, which was introduced in the 1950s as a means of assuring the quality of products built for the US military.
However, many organizations and companies rely on ISO9000 registration to provide assurance of the quality of products and services they buy and to indicate quality of their products and services.
Registration is to the relevant standard within the ISO9000 'family'. ISO9001 is the standard applicable to organizations that design, develop and manufacture products. We will refer to 'ISO9000 registration' as a general indication.
ISO9000 does not specifically address the quality of products and services, nor does it prescribe methods for achieving quality, such as design analysis, test and quality control. It describes, in very general terms, the system that should be in place to assure quality. In principle, there is nothing in the standard to prevent an organization from producing poor quality goods or services, so long as written procedures exist and are followed. An organization with an effective quality system would normally be more likely to take corrective action and to improve processes and service, than would one which is disorganized. However, the fact of registration should not be considered as a guarantee of quality.
In the ISO9000 approach, suppliers' quality management systems (organization, procedures, etc.) are audited by independent 'third party' assessors, who assess compliance with the standard and issue certificates of registration. Certain organizations are 'accredited' as 'certification bodies' by the appropriate national accreditation services. The justification given for third party assessment is that it removes the need for every customer to perform his own assessment of all of his suppliers. However, a matter as important as quality cannot safely be left to be assessed infrequently by third parties, who are unlikely to have the appropriate specialist knowledge, and who cannot be members of the joint supplier-purchaser team. The total quality management (TQM) philosophy (see Section 5) demands close, ongoing partnership between suppliers and purchasers.
Since its inception, ISO9000 has generated considerable controversy. The effort and expense that must be expended to obtain and maintain registration tend to engender the attitude that optimal standards of quality have been achieved. The publicity that typically goes with initial certification of a business supports this belief.
The objectives of the organization, and particularly of the staff directly involved in obtaining and maintaining registration, are directed at the maintenance of procedures and at audits to ensure that staff work to them. It can become more important to work to procedures than to develop better ways of working. However, some organizations have generated real improvements as a result of certification. So why is the approach so widely used? The answer is partly cultural and partly coercive.
The cultural pressure derives from the tendency to believe that people perform better when told what to do, rather than when they are given freedom and the necessary skills and motivation to determine the best ways to perform their work. This belief stems from the concept of scientific management, as described in Drucker (1955) and O'Connor (2004).
The coercion to apply the standard comes from several directions. In practice, many agencies demand that bidders for contracts must be registered. All contractors and their subcontractors supplying the UK Ministry of Defense must be registered, since the MoD decided to drop its own assessments in favor of the third party approach, and the US Department of Defense decided to apply ISO9000 in place of MIL-STD-Q9858. Several large companies, as well as public utilities, demand that their suppliers are registered to ISO9000 or to industry versions, such as QS9000 for automotive and TL9000 for telecommunications applications. Defenders of ISO9000 say that the total quality management (TQM) approach is too severe for most organizations, and that ISO9000 can provide a 'foundation' for a subsequent total quality effort. However, the foremost teachers of modern quality management all argued against this view. They point out that any organization can adopt the TQM philosophy, and that it will lead to greater benefit s than will registration to the standard, and at lower costs.
There are many books in publication that describe ISO9000 and its application: Hoyle (2009) is an example.
5.3 IEC61508 (Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems)
IEC61508 is the international standard to set requirements for design, development, operation and maintenance of 'safety-related' control and protection systems which are based on electrical, electronics and software technologies. A system is 'safety-related' if any failure to function correctly can present a hazard to people.
Thus, systems such as railway signaling, vehicle braking, aircraft controls, fire detection, machine safety interlocks, process plant emergency controls and car airbag initiation systems would be included. The standard lays down criteria for the extent to which such systems must be analyzed and tested, including the use of independent assessors, depending on the criticality of the system. It also describes a number of methods for analyzing hardware and software designs.
The extent to which the methods are to be applied is determined by the required or desired safety integrity level (SIL) of the safety function, which is stated on a range from 1 to 4. SIL 4 is the highest, relating to a 'target failure measure' between 10-5 and 10-4 per demand, or 10-9 and 10-8 per hour. For SIL 1 the figures are 2, - and 10-6, - 10-5.
For the quantification of failure probabilities reliability prediction methods such as those covered in Section 6 are recommended. The methods listed include 'use of well-tried components' (recommended for all SILs), 'simulation' (recommended for SIL 2, 3 and 4), and 'modularization' ('highly recommended' for all SILs).
In the early 2000's ISO produced an automotive version of this standard, IEC 26262. It addresses functional safety in a way similar to IEC61508 with appropriate adaptations for road vehicles.
The value and merits for both standards are somewhat questionable. The methods described are often inconsistent with accepted best industry practices. The issuing of these standards has lead to a growth of bureaucracy, auditors and consultants, and increased costs. It’s unlikely to generate any improvements in safety, for the same reasons that ISO9000 does not necessarily improve quality. However, they exist and compliance is often mandatory, so system designers must be aware of them and ensure that the requirements are met.
6 Specifying Reliability
In order to ensure that reliability is given appropriate attention and resources during design, development and manufacture, the requirement must be specified. Before describing how to specify reliability adequately, we will cover some of the ways of how not to do it:
1. Don’t write vague requirements, such as 'as reliable as possible', 'high reliability is to be a feature of the design', or 'the target reliability is to be 99%'. Such statements don’t provide assurance against reliability being compromised.
2. Don’t write unrealistic requirements. 'Won’t fail under the specified operation conditions' is a realistic requirement in many cases. However, an unrealistically high reliability requirement for, say, a complex electronic equipment won’t be accepted as a credible design parameter, and could therefore be ignored.
The reliability specification must contain:
1. A definition of failure related to the product's function. The definition should cover all failure modes relevant to the function.
2. A full description of the environments in which the product will be stored, transported, operated and maintained.
3 A statement of the reliability requirement, and/or a statement of failure modes and effects which are particularly critical and which must therefore have a very low probability of occurrence. Examples of reliability metrics to be used are discussed in Section 14.2. GMW3172 (2004) can be used as an example of a detailed reliability specification. Also UK Defense Standard 00-40 covers the preparation of reliability specifications in detail.
6.1 Definition of Failure
Care must be taken in defining failure to ensure that the failure criteria are unambiguous. Failure should always be related to a measurable parameter or to a clear indication. A seized bearing indicates itself clearly, but a leaking seal might or might not constitute a failure, depending upon the leak rate, or whether or not the leak can be rectified by a simple adjustment. An electronic equipment may have modes of failure which don’t affect function in normal operation, but which may do so under other conditions. For example, the failure of a diode used to block transient voltage spikes may not be apparent during functional test, and will probably not affect normal function. Defects such as changes in appearance or minor degradation that don’t affect function are not usually relevant to reliability. However, sometimes a perceived degradation is an indication that failure will occur and therefore such incidents can be classified as failures.
Inevitably there will be subjective variations in assessing failure, particularly when data are not obtained from controlled tests. For example, failure data from repairs carried out under warranty might differ from data on the same equipment after the end of the warranty period, and both will differ from data derived from a controlled reliability demonstration. The failure criteria in reliability specifications can go a long way to reducing the uncertainty of relating failure data to the specification and in helping the designer to understand the reliability requirement.
6.2 Environmental Specifications
The environmental specification must cover all aspects of the many loads and other effects that can influence the product's strength or probability of failure. Without a clear definition of the conditions which the product will face, the designer won’t be briefed on what he is designing against. Of course, aspects of the environmental specification might sometimes be taken for granted and the designer might be expected to cater for these conditions without an explicit instruction. It’s generally preferable, though, to prepare a complete environmental specification for a new product, since the discipline of considering and analyzing the likely usage conditions is a worthwhile exercise if it focuses attention on any aspect which might otherwise be overlooked in the design. Environments are covered in Section 7.3.2. For most design groups only a limited number of standard environmental specifications is necessary. For example, the environmental requirements and methods of test for military equipment are covered in specifications such as US MIL-STD-810 and UK Defense Standard 07-55. Another good example is the automotive validation standard GMW3172 (2004) mentioned earlier.
The environments to be covered must include handling, transport, storage, normal use, foreseeable misuse, maintenance and any special conditions. For example, the type of test equipment likely to be used, the skill level of users and test technicians, and the conditions under which testing might be performed should be stated if these factors might affect the observed reliability.
6.3 Stating the Reliability Requirement
The reliability requirement should be stated in a way which can be verified, and which makes sense relative to the use of the product. For example, there is little point in specifying a time between failures if the product's operation will be measured only in distance travelled, or if it won’t be measured at all (either in a reliability demonstration or during service).
Levels of reliability can be stated as a success ratio, or as a life. For 'one-shot' items the success ratio is the only relevant criterion.
Reliability specifications based on life parameters must be framed in relation to the appropriate life distributions. The examples of reliability metrics appropriate for reliability specifications are covered in Section 14.2.
Specified life parameters must clearly state the life characteristic. For example, the life of a switch, a sequence valve or a data recorder cannot be usefully stated merely as a number of hours. The life must be related to the duty cycle (in these cases switch reversals and frequency, sequencing operations and frequency, and anticipated operating cycles on record, playback and switch on/off). The life parameter may be stated as some time-dependent function, For example distance travelled, switching cycles, load reversals, or it may be stated as a time, with a stipulated operating cycle.
7 Contracting for Reliability Achievement
Users of equipment which can have high unreliability costs have for some time imposed contractual conditions relative to reliability. Of course, every product warranty is a type of reliability contract. However, contracts which stipulate specific incentives or penalties related to reliability achievement have been developed, mainly by the military, but also by other major equipment users such as airlines and public utilities.
The most common form of reliability contract is one which ties an incentive or penalty to a reliability demonstration. The demonstration may either be a formal test (see the methods covered in Section 14) or may be based upon the user's experience. In either case, careful definition of what constitutes a relevant failure is necessary, and a procedure for failure classification must be agreed. If the contract is based only on incentive payments, it can be agreed that the customer will classify failures and determine the award, since no penalty is involved. One form of reliability incentive contract is that used for spacecraft, whereby the customer pays an incentive fee for successful operation for up to, say, two years.
Incentive payments have advantages over incentive/penalty arrangements. It’s important to create a positive motivation, rather than a framework which can result in argument or litigation, and incentives are preferable in this respect. Also, an incentive is easier to negotiate, as it’s likely to be accepted as offered. Incentive payments can be structured so that, whilst they represent a relatively small percentage of the customer's saving due to increased reliability, they provide a substantial increase in profit to the supplier. The receipt of an incentive fee has significant indirect advantages, as a morale booster and as a point worth quoting in future bid situations. A typical award fee structure is shown in FIG. 4.
When planning incentive contracts it’s necessary to ensure that other performance aspects are sufficiently well specified and, if appropriate, also covered by financial provisions such as incentives or guarantees, so that the supplier is not motivated to aim for the reliability incentive at the expense of other features.
Incentive contracting requires careful planning so that the supplier's motivation is aligned with the customer's requirements. The parameter values selected must provide a realistic challenge and the fee must be high enough to make extra effort worthwhile.
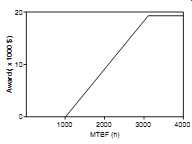
FIG. 4 Reliability incentive structure.
7.1 Warranty Improvement Contracts
Billions of dollars are spent by manufacturers on warranty each year. Therefore in many industries manufacturers make the efforts to motivate their suppliers to improve their reliability and consequently reduce warranty. For example, some automotive manufacturers would cover the cost of warranty up to a certain failure rate (e.g., one part per thousand vehicles per year), and everything above that rate would be the supplier's responsibility. In recent years there have been more and more efforts on the part of manufacturers to force their suppliers to pay their 'fair share' of the warranty costs. Warranty Week (2011) newsletter publishes a comprehensive coverage of finance and management aspects of warranty for various industries and regions.
7.2 Total Service Contracts
A total service supply contract is one in which the supplier is required to provide the system, as well as all of the support. The purchaser does not specify a quantity of systems, but a level of availability. Railway rolling stock contracts in Europe epitomize the approach: the rail company specifies a timetable, and the supplier must determine and build the appropriate number of trains, provide all maintenance and other logistic support, including staffing and running the maintenance depots, spares provisioning, and so on.
All the train company does is operate the trains. The contracts include terms to cover failures to meet the timetable due to train failures or non-availability. Similar contracts are used for the supply of electronic instrumentation to large buyers, medical equipment to hospitals, and some military applications such as trainer aircraft.
A total supply contract places the responsibility and risk aspects of reliability firmly with the supplier, and can therefore be highly motivating. However, there can be long-term disadvantages to the purchaser. The purchaser's organization can lose the engineering knowledge that might be important in optimizing trade-offs between engineering and operational aspects, and in planning future purchases. When the interface between engineering and operation is purely financial and legal, with separate companies working to different business objectives, conflicts of interests can arise, leading to sub-optimization and inadequate co-operation. Since the support contract, once awarded, cannot be practically changed or transferred, the supplier is in a monopoly situation. The case of Railtrack in the UK, which 'outsourced' all rail and other infrastructure maintenance to contractors, and in the process lost the knowledge necessary for effective management, resulting directly in a fatal crash and a network-wide crisis due to cracked rails, provides a stark warning of the potential dangers of the approach. It’s interesting that, by contrast, the airlines continue to perform their own maintenance, and the commercial aircraft manufacturers concentrate on the business they know best.
8 Managing Lower-Level Suppliers
Lower-level suppliers can have a major influence on the reliability of systems. It’s quite common that 80% or more of failures of systems such as trains, aircraft, ships, factory and infrastructure systems, and so on can be 'bought' from the lower-level suppliers. In smaller systems, such as machines and electronic equipment, items such as engines, hydraulic pumps and valves, power supplies, displays, and so on are nearly always bought from specialist suppliers, and their failures contribute to system unreliability. Therefore it’s essential that the project reliability effort is directed as much to these suppliers as to internal design, development and manufacturing. Continuous globalization and outsourcing also affect the work with lower-level suppliers. It’s not uncommon these days to have suppliers located all over the globe including regions with little knowledge depth regarding design and manufacturing processes and with a less robust quality system in place.
To ensure that lower-level suppliers make the best contributions to system reliability, the following guide lines should be applied:
1. Rely on the existing commercial laws that govern trading relationships to provide assurance. In all cases this provides for redress if products or services fail to achieve the performance specified or implied.
Therefore, if failures do occur, action to improve or other appropriate action can be demanded. In many cases warranty terms can also be exercised. However, if the contract stipulates a value of reliability to be achieved, such as MTBF or maximum proportion failing, then in effect failures are being invited.
When failures do occur there is a tendency for discussion and argument to concentrate on statistical interpretations and other irrelevancies, rather than on engineering and management actions to prevent recurrence. We should specify success, not failure.
2. Don’t rely solely on ISO 9000 or similar schemes to provide assurance. As explained above, these approaches provide no direct assurance of product or service reliability or quality.
3. Engineers should manage the selection and purchase of engineering products. It’s a common practice for companies to assign this function to a specialized purchasing organization, and design engineers must submit specifications to them. This is based on the argument that engineers might not have knowledge of the business aspects that purchasing specialists do. However, only the engineers concerned can be expected to understand the engineering aspects, particularly the longer-term impact of reliability. Engineers can quickly be taught sufficient purchasing knowledge, or can be supported by purchasing experts, but purchasing people cannot be taught the engineering knowledge and experience necessary for effective selection of engineering components and sub-systems.
4. Don’t select suppliers on the basis of the price of the item alone. (This is point number 4 of Deming's famous '14 points for managers', Deming, 1987.) Suppliers and their products must be selected on the basis of total value to the system, over its expected life. This includes performance, reliability, support, and so on as well as price.
5. Create long-term partnerships with suppliers, rather than seek suppliers on a project-by-project basis or change suppliers for short-term advantage. In this way it becomes practicable to share information, rewards and risks, to the long-term benefit of both sides. Suppliers in such partnerships can teach application details to the system designers, and can respond more effectively to their requirements.
These points are discussed in more detail in O'Connor (2004).
9. The Reliability Manual
Just as most medium to large design and development organizations have internal manuals covering design practices, organizational structure, Quality Assurance (QA) procedures, and so on, so reliability management and engineering should be covered. Depending on the type of product and the organization adopted, reliability can be adequately covered by appropriate sections in the engineering and QA manuals, or a separate reliability manual may be necessary. In-house reliability procedures should not attempt to teach basic principles in detail, but rather should refer to appropriate standards and literature, which should of course then be made available.
If reliability program activities are described in military, national or industry standards, these should be referred to and followed when appropriate. The bibliographies at the end of each section of this guide list the major references.
The in-house documents should cover, as a minimum the following subjects:
- 1 Corporate policy for reliability.
- 2 Organization for reliability.
- 3 Reliability procedures in design (e.g. design analysis, parts derating policy, parts, materials and process selection approval and review, critical items listing, design review).
- 4 Reliability test procedures.
- 5 Reliability data collection, analysis and action system, including data from test, warranty, etc.
The written procedures must state, in every case, who carries responsibility for action and who is responsible for providing the resources and capability. They must also state who provides supporting services. A section from the reliability manual may appear as shown in Table 1.
=====
Table 1 Reliability manual: responsibilities.
Department responsible Task Reference Prime Resources Support Stress analysis (electronic) Procedure XX Project design Reliability, Reliability, Reliability test Procedure YY Reliability Environmental test Project design Reliability data Procedure ZZ Reliability, Reliability QA,
=====
10. The Project Reliability Plan
Every project should create and work to a written reliability plan. It’s normal for customer-funded development projects to include a requirement for a reliability plan to be produced.
The reliability plan should include:
- 1 A brief statement of the reliability requirement.
- 2 The organization for reliability.
- 3 The reliability activities that will be performed (design analysis, test, reports).
- 4 The timing of all major activities, in relation to the project development milestones.
- 5 Reliability management of suppliers.
- 6 The standards, specifications and internal procedures (e.g. the reliability manual) which will be used, as well as cross-references to other plans such as for test, safety, maintainability and quality assurance.
When a reliability plan is submitted as part of a response to a customer request for proposals (RFP) in a competitive bid situation, it’s important that the plan reflects complete awareness and understanding of the requirements and competence in compliance.
A reliability plan prepared as part of a project development, after a contract has been accepted, is more comprehensive than an RFP response, since it gives more detail of activities, time-scales and reporting. Since the project reliability plan usually forms part of the contract once accepted by the customer, it’s important that every aspect is covered clearly and explicitly.
A well-prepared reliability plan is useful for instilling confidence in the supplier's competence to undertake the tasks, and for providing a sound reliability management plan for the project to follow.
Sub-section 6 shows an example of a reliability and maintainability plan, including safety aspects.
10.1 Specification Tailoring
Specification tailoring is a term used to describe the process of suggesting alternatives to the customer's specification. 'Tailoring' is often invited in RFPs and in development contracts. A typical example occurs when a customer specifies a system and requires a formal reliability demonstration. If a potential supplier can supply a system for which adequate in-service reliability records exist, the specification could be tailored by proposing that these data be used in place of the reliability demonstration. This could save the customer the considerable expense of the demonstration. Also, it’s not uncommon for a potential supplier to take an exception to certain requirements in the RFP if they don’t appear feasible or possible for the supplier to implement. Other examples might arise out of trade-off studies, which might show, for instance, that a reduced performance parameter could lead to cost savings or reliability improvement. Next>>
Prev. | Next
Article Index HOME