| HOME | Project Management Data Warehousing / Mining Software Testing | Technical Writing |
|
In this section, we examine: • what we mean by "software engineering" • software engineering’s track record • what we mean by “good software” • why a systems approach is important • how software engineering has changed since the 1970s Software pervades our world, and we sometimes take for granted its role in making our lives more comfortable, efficient, and effective. For example, consider the simple tasks involved in preparing toast for breakfast. The code in the toaster controls how brown the bread will get and when the finished product pops up. Programs control and regulate the delivery of electricity to the house, and software bills us for our energy usage. In fact, we may use automated programs to pay the electricity bill, to order more groceries, and even to buy a new toaster! Today, software is working both explicitly and behind the scenes in virtually all aspects of our lives, including the critical systems that affect our health and well-being. For this reason, software engineering is more important than ever. Good software engineering practices must ensure that software makes a positive contribution to how we lead our lives. This guide highlights the key issues in software engineering, describing what we know about techniques and tools, and how they affect the resulting products we build and use. We will look at both theory and practice: what we know and how it is applied in a typical software development or maintenance project. We will also examine what we do not yet know, but what would be helpful in making our products more reliable, safe, useful, and accessible. We begin by looking at how we analyze problems and develop solutions. Then we investigate the differences between computer science problems and engineering ones. Our ultimate goal is to produce solutions incorporating high-quality software, and we consider characteristics that contribute to the quality. We also look at how successful we have been as developers of software systems. By examining several examples of software failure, we see how far we have come and how much farther we must go in mastering the art of quality software development. Next, we look at the people involved in software development. After describing the roles and responsibilities of customers, users, and developers, we turn to a study of the system itself. We see that a system can be viewed as a group of objects related to a set of activities and enclosed by a boundary. Alternatively, we look at a system with an engineer’s eye; a system can be developed much as a house is built. Having defined the steps in building a system, we discuss the roles of the development team at each step. Finally, we discuss some of the changes that have affected the way we practice software engineering. We present Wasserman’s eight ideas to tie together our practices into a coherent whole. 1. WHAT IS SOFTWARE ENGINEERING? As software engineers, we use our knowledge of computers and computing to help solve problems. Often the problem with which we are dealing is related to a computer or an existing computer system, but sometimes the difficulties underlying the problem have nothing to do with computers. Therefore, it is essential that we first understand the nature of the problem. In particular, we must be very careful not to impose computing machinery or techniques on every problem that comes our way. We must solve the problem first. Then, if need be, we can use technology as a tool to implement our solution. For the remainder of this guide, we assume that our analysis has shown that some kind of computer system is necessary or desirable to solve a particular problem at hand. Solving Problems Most problems are large and sometimes tricky to handle, especially if they represent something new that has never been solved before. So we must begin investigating it by analyzing it, that is, by breaking the problem into pieces that we can understand and try to deal with. We can thus describe the larger problem as a collection of small problems and their interrelationships. FIG. 1 illustrates how analysis works. It is important to remember that the relationships (the arrows in the figure, and the relative position of the subproblems) are as essential as the subproblems themselves. Sometimes, it is the relationships that hold the clue to how to solve the larger problem, rather than simply the nature of the subproblems. Once we have analyzed the problem, we must construct our solution from components that address the problem’s various aspects. FIG. 2 illustrates this reverse process: Synthesis is the putting together of a large structure from small building blocks. As with analysis, the composition of the individual solutions may be as challenging as finding the solutions themselves. To see why, consider the process of writing a novel. The dictionary contains all the words that you might want to use in your writing. But the most difficult part of writing is deciding how to organize and compose the words into sentences, and likewise the sentences into paragraphs and sections to form the complete guide. Thus, any problem-solving technique must have two parts: analyzing the problem to determine its nature, and then synthesizing a solution based on our analysis.
To help us solve a problem, we employ a variety of methods, tools, procedures, and paradigms. A method or technique is a formal procedure for producing some result. For example, a chef may prepare a sauce using a sequence of ingredients combined in a carefully timed and ordered way so that the sauce thickens but does not curdle or separate. The procedure for preparing the sauce involves timing and ingredients but may not depend on the type of cooking equipment used. A tool is an instrument or automated system for accomplishing something in a better way. This “better way” can mean that the tool makes us more accurate, more efficient, or more productive or that it enhances the quality of the resulting product. For example, we use a typewriter or keyboard and printer to write letters because the resulting documents are easier to read than our handwriting. Or we use a pair of scissors as a tool because we can cut faster and straighter than if we were tearing a page. How ever, a tool is not always necessary for making something well. For example, a cooking technique can make a sauce better, not the pot or spoon used by the chef. A procedure is like a recipe: a combination of tools and techniques that, in concert, produce a particular product. For instance, as we will see in later sections, our test plans describe our test procedures; they tell us which tools will be used on which data sets under which circumstances so we can determine whether our software meets its requirements. Finally, a paradigm is like a cooking style; it represents a particular approach or philosophy for building software. Just as we can distinguish French cooking from Chinese cooking, so too do we distinguish paradigms like object-oriented development from procedural ones. One is not better than another; each has its advantages and disadvantages, and there may be situations when one is more appropriate than another. Software engineers use tools, techniques, procedures, and paradigms to enhance the quality of their software products. Their aim is to use efficient and productive approaches to generate effective solutions to problems. In the sections that follow, we will highlight particular approaches that support the development and maintenance activities we de scribe. An up-to-date set of pointers to tools and techniques is listed in this guide’s associated home page on the World Wide Web. Where Does the Software Engineer Fit In? To understand how a software engineer fits into the computer science world, let us look to another discipline for an example. Consider the study of chemistry and its use to solve problems. The chemist investigates chemicals: their structure, their interactions, and the theory behind their behavior. Chemical engineers apply the results of the chemist’s studies to a variety of problems. Chemistry as viewed by chemists is the object of study. On the other hand, chemistry for a chemical engineer is a tool to be used to address a general problem (which may not even be “chemical” in nature). We can view computing in a similar light. We can concentrate on the computers and programming languages themselves, or we can view them as tools to be used in designing and implementing a solution to a problem. Software engineering takes the latter view, as shown in FIG. 3. Instead of investigating hardware design or proving theorems about how algorithms work, a software engineer focuses on the computer as a problem-solving tool. We will see later in this section that a software engineer works with the functions of a computer as part of a general solution, rather than with the structure or theory of the computer itself.
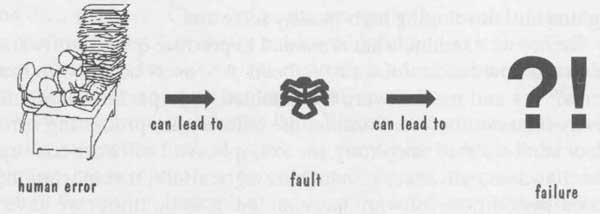
2. HOW SUCCESSFUL HAVE WE BEEN? Writing software is an art as well as a science, and it is important for you as a student of computer science to understand why. Computer scientists and software engineering re searchers study computer mechanisms and theorize about how to make them more productive or efficient. However, they also design computer systems and write programs to perform tasks on those systems, a practice that involves a great deal of art, ingenuity, and skill. There may be many ways to perform a particular task on a particular system, but some are better than others. One way may be more efficient, more precise, easier to modify, easier to use, or easier to understand. Any hacker can write code to make some thing work, but it takes the skill and understanding of a professional software engineer to produce code that is robust, easy to understand and maintain, and does its job in the most efficient and effective way possible. Consequently, software engineering is about designing and developing high-quality software. Before we examine what is needed to produce quality software systems, let us look back to see how successful we have been. Are users happy with their existing software systems? Yes and no. Software has enabled us to perform tasks more quickly and effectively than ever before. Consider life before word processing, spreadsheets, electronic mail, or sophisticated telephony, for example. And software has supported life-sustaining or life-saving advances in medicine, agriculture, transportation, and most other industries. In addition, software has enabled us to do things we have never done before: microsurgery, multimedia education, robotics, and more. However, software is not without its problems. Often systems function, but not exactly as expected. We all have heard stories of systems that just barely work. And we all have written faulty programs: code that still contains mistakes, but that is good enough? For a passing grade or for demonstrating the feasibility of an approach. Clearly, such behavior is not acceptable when developing a system for delivery to a customer. There is an enormous difference between an error in a class project and one in a large software system. In fact, software faults and the difficulty in producing fault-free software are frequently discussed in the literature and in the hallways. Some faults are merely annoying; others cost a great deal of time and money. Still others are life-threatening. Sidebar 1 explains the relationships among faults, errors and failures. Let us look at a few examples of failures to see what is going wrong and why. === ==== SIDEBAR 1 TERMINOLOGY FOR DESCRIBING BUGS Often we talk about bugs in software meaning many things that depend on the context. A bug can be a mistake in interpreting a requirement a syntax error in a piece of code or the (as yet unknown) cause of a system crash. The IEEE has suggested a standard terminology (in IEEE Standard 729) for describing bugs ‘in our software products (IEEE 1983). A fault occurs when a human makes a mistake called an error in performing some software activity. For example a designer may misunderstand a requirement and create a design that does not match the actual intent of the requirements analyst and the user. This design fault is an encoding of the error and it can lead to other faults such as incorrect code and an incorrect description in a user manual. Thus, a single error can generate many faults and a fault can reside in any development or maintenance product. A failure is a departure from the system s required behavior It can be discovered before or after system delivery during testing or during operation and maintenance. Since the requirements documents can contain faults a failure indicates that the system is not performing as required even though it may be performing as specified. Thus a fault is an inside view of the system as seen by the eyes of the developers where as a failure is an outside view a problem that the user sees. Not every fault corresponds to a failure for example if faulty code is never executed or a particular state is never entered then the fault will never cause the code to fail. Figure 4 shows the genesis of a failure. ==== === In the early 1980s, the United States Internal Revenue Service (IRS) hired Sperry Corporation to build an automated federal income tax form processing system. Ac cording to the Washington Post, the “system has proved inadequate to the workload, cost nearly twice what was expected and must be replaced soon” (Sawyer 1985). In 1985, an extra $90 million was needed to enhance the original $103 million worth of Sperry equipment. In addition, because the problem prevented the IRS from returning refunds to taxpayers by the deadline, the IRS was forced to pay $40.2 million in interest and $22.3 million in overtime wages for its employees who were trying to catch up. In 1996, the situation had not improved. The Los Angeles Times reported on March 29 that there was still no master plan for the modernization of IRS computers, only a six-thousand-page technical document. Congressman Jim Lightfoot called the project “a $4-billion fiasco that is floundering because of inadequate planning” (Vartabedian 1996). We will see in Section 2 why project planning is essential to the production of quality software. For many years, the public accepted the infusion of software in their daily lives with little question. But President Reagan’s proposed Strategic Defense Initiative (SDI) heightened the public’s awareness of the difficulty of producing a fault-free software system. Popular newspaper and magazine reports (such as Jacky 1985, Parnas 1985, Rensburger 1985) expressed skepticism in the computer science community. And now, 20 years later, as the U.S. Congress is asked to allocate funds to build a similar system, many computer scientists and software engineers continue to believe there is no way to write and test the software to guarantee adequate reliability. For example, many software engineers think that an antiballistic missile system would require at least ten million lines of code; some estimates range as high as one hundred million. By comparison, the software supporting the American space shuttle consists of three million lines of code, including computers on the ground controlling the launch and the flight; there were one hundred thousand lines of code in the shuttle it self in 1985 (Rensburger 1985). Thus, an antimissile software system would require the testing of an enormous amount of code. Moreover, the reliability constraints would be impossible to test. To see why, consider the notion of safety-critical software. Typically, we say that something that is safety-critical (i.e., something whose failure poses a threat to life or health) should have a reliability of at least 10^9 As we shall see in Section 9, this terminology means that the system can fail no more often than once in 10^9 hours of operation. To observe this degree of reliability, we would have to run the system for at least 10^9 hours to verify that it does not fail. But 10^9 hours is over 114,000 years—far too long as a testing interval! We will also see in Section 9 that helpful technology can become deadly when software is improperly designed or programmed. For example, the medical community was aghast when the Therac-25, a radiation therapy and X-ray machine, malfunctioned and killed several patients. The software designers had not anticipated the use of several arrow keys in nonstandard ways; as a consequence, the software retained its high settings and issued a highly concentrated dose of radiation when low levels were intended (Leveson and Turner 1993). A similar, dangerous example of unanticipated use and its consequences was published in Pilot magazine and reported in the Risks Forum (Pilot 1996).Two police officers in the Lothian and Borders region of Scotland were using a radar gun to identify speeding motorists on the Berwickshire moors. Suddenly, their radar gun locked up, with a speed indication of over 300 miles per hour. Seconds later, a low-flying Harrier jet flew by. The Harrier’s target seeker had recognized the radar and thought it to belong to an “enemy”; fortunately, the Harrier was operating unarmed, since normal behavior would have triggered an automatic retaliatory missile! Unanticipated use of the system should be considered throughout software de sign activities. These uses can be handled in at least two ways: by stretching your imagination to think of how the system can be abused (as well as used properly), and by assuming that the system will be abused and designing the software to handle the abuses. We discuss these approaches in Section 8. Although many vendors strive for zero-defect software, in fact most software products are not fault-free. Market forces encourage software developers to deliver products quickly, with little time to test thoroughly. Typically, the test team will be able to test only those functions most likely to be used, or those that are most likely to endanger or irritate users. For this reason, many users are wary of installing the first version of code, knowing that the “bugs” will not be worked out until the second version. Furthermore, the modifications needed to fix known faults are sometimes so difficult to make that it is easier to rewrite a whole system than to change existing code. We will investigate the issues involved in software maintenance in Section 11. In spite of some spectacular successes and the overall acceptance of software as a fact of life, there is still much room for improvement in the quality of the software we produce. For example, lack of quality can be costly; the longer a fault goes undetected, the more expensive it is to correct. In particular, the cost of correcting an error made during the initial analysis of a project is estimated to be only one-tenth the cost of correcting a similar error after the system has been turned over to the customer. Unfortunately, we do not catch most of the errors early on. Half of the cost of correcting faults found during testing and maintenance comes from errors made much earlier in the life of a system. In Sections 12 and 13 we will look at ways to evaluate the effectiveness of our development activities and improve the processes to catch mistakes as early as possible. One of the simple but powerful techniques we will propose is the use of review and inspection. Many students are accustomed to developing and testing software on their own. But their testing may be less effective than they think. For example, Fagan studied the way in which faults have been detected in the past. He discovered that testing a pro gram by running it with test data revealed only about a fifth of the faults located during systems development. However, peer review, the process whereby colleagues examine and comment on each other’s design and code, uncovered the remaining four out of five faults found (Fagan 1986). Thus, the quality of your software can be increased dramatically just by having your colleagues review your work. We will learn more in later sections about how the review and inspection processes can be used after each major development step to find and fix faults as early as possible. And we will see in Section 13 how to improve the inspection process itself. 3. WHAT IS GOOD SOFTWARE? Just as manufacturers look for ways to assure the quality of the products they produce, so too must software engineers find methods to assure that their products are of acceptable quality and utility. Thus, good software engineering must always include a strategy for producing quality software. But before we can devise a strategy, we must understand what we mean by quality software. Sidebar 2 shows us how perspective influences what we mean by “quality.” In this section, we examine what distinguishes good software from bad. == === === SIDEBAR 2--PERSPECTIVES ON QUALITY Garvin (1984) has written about how different people perceive quality. He describes quality from five different perspectives: • the transcendental view where quality is something we can recognize but not define • the user view where quality is fitness for purpose • the manufacturing view where quality is conformance to specification • the product view where quality is tied to inherent product characteristics • the value based view where quality depends on the amount the customer is willing to pay for it The transcendental view is much like Plato s description of the ideal or Aristotle s concept of form In other words, Just as every actual table is an approximation of an ideal table we can think of software quality as an ideal toward which we strive however we may never be able to implement it completely The transcendent view is ethereal, in contrast to the more concrete view of the user We take a user view when we measure product characteristics such as defect density or reliability in order to understand the overall product quality The manufacturing view looks at quality during production and after delivery. In particular, it examines whether the product was built right the first time avoiding costly rework to fix delivered faults. Thus, the manufacturing view is a process view, advocating conformance to good process. However there is little evidence that conformance to process actually results in products with fewer faults and failures process may indeed lead to high quality products but it may possibly institutionalize the production of mediocre products. We examine some of these issues in Section 12. The user and manufacturing views look at the product from the outside but the product view peers inside and evaluates a product s inherent characteristics. This view is the one often advocated by software metrics experts they assume that good internal quality indicators will lead to good external ones such as reliability and maintainability. However more research is needed to verify these assumptions and to determine which aspects of quality affect the actual product’s use. We may have to develop models that link the product view to the user view. Customers or marketers often take a user view of quality. Researchers sometimes hold a product view, and the development team has a manufacturing view. If the differences in viewpoints are not made explicit, then confusion and misunderstanding can lead to bad decisions and poor products. The value-based view can link these disparate pictures of quality. By equating quality to what the customer is willing to pay, we can look at trade-offs between cost and quality, and we can manage conflicts when they arise. Similarly, purchasers compare product costs with potential benefits, thinking of quality as value for money. = = = = == Kitchenham and Pfleeger (1996) investigated the answer to this question in their introduction to a special issue of IEEE Software on quality. They note that the context helps to determine the answer. Faults tolerated in word processing software may not be acceptable in safety-critical or mission-critical systems. Thus, we must consider quality j in at least three ways: the quality of the product, the quality of the process that results in the product, and the quality of the product in the context of the business environment in which the product will be used. The Quality of the Product We can ask people to name the characteristics of software that contribute to its overall quality, but we are likely to get different answers from each person we ask. This difference occurs because the importance of the characteristics depends on who is analyzing the software. Users judge software to be of high quality if it does what they want in a way that is easy to learn and easy to use. However, sometimes quality and functionality are intertwined; if something is hard to learn or use but its functionality is worth the trouble, then it is still considered to have high quality. We try to measure software quality, so we can compare one product with another. To do so, we identify particular aspects of the system that contribute to the overall quality. Thus, when measuring software quality, users assess such external characteristics as the number of failures and type of failures. For example, they may define failures as minor, major, and catastrophic, and hope that any failures that occur are only minor ones. The software must also be judged by those who are designing and writing the code and by those who must maintain the programs after they are written. These practitioners tend to look at internal characteristics of the products, sometimes even before the product is delivered to the user. In particular, practitioners often look at numbers and types of faults for evidence of a product’s quality (or lack of it). For example, developers track the number of faults found in requirements, design, and code inspections and use them as indicators of the likely quality of the final product. For this reason, we often build models to relate the user’s external view to the developer’s internal view of the software. FIG. 5 is an example of an early quality model built by McCall and his colleagues to show how external quality factors (on the left- hand side) relate to product quality criteria (on the right-hand side). McCall associated each right-hand criterion with a measurement to indicate the degree to which an element of quality was addressed (McCall, Richards, and Walters 1977). We will examine sever al product quality models in Section 12. The Quality of the Process There are many activities that affect the ultimate product quality; if any of the activities go awry, the product quality may suffer. For this reason, many software engineers feel that the quality of the development and maintenance process is as important as product quality. One of the advantages of modeling the process is that we can examine it and look for ways to improve it. For example, we can ask questions such as: • Where and when are we likely to find a particular kind of fault? • How can we find faults earlier in the development process? • How can we build in fault tolerance so that we minimize the likelihood that a fault will become a failure? • Are there alternative activities that can make our process more effective or efficient at assuring quality? These questions can be applied to the whole development process, or to a sub-process, such as configuration management, reuse, or testing; we will investigate these processes in later sections.
In the 1990s, there was a well-publicized focus on process modeling and process improvement in software engineering. Inspired by the work of Deming and Juran, and implemented by companies such as IBM, process guidelines such as the Capability Maturity Model (CMM), ISO 9000, and Software Process Improvement and Capability determination (SPICE) suggested that by improving the software development process, we can improve the quality of the resulting products. In Section 2, we will see how to identify relevant process activities and model their effects on intermediate and final products. Sections 12 and 13 will examine process models and improvement frame works in depth. Quality in the Context of the Business Environment When the focus of quality assessment has been on products and processes, we usually measure quality with mathematical expressions involving faults, failures, and timing. Rarely is the scope broadened to include a business perspective, where quality is viewed in terms of the products and services being provided by the business in which the soft ware is embedded. That is, we look at the technical value of our products, rather than more broadly at their business value, and we make decisions based only on the resulting products’ technical quality. In other words, we assume that improving technical quality will automatically translate into business value. Several researchers have taken a close look at the relationships between business value and technical value. For example, Simmons interviewed many Australian businesses to determine how they make their information technology-related business decisions. She proposes a framework for understanding what companies mean by “business value” (Simmons 1996). In a report by Favaro and Pfleeger (1997), Steve Andriole, chief information officer for Cigna Corporation, a large U.S. insurance company, described how his company distinguishes technical value from business value: We measure the quality [ our software] by the obvious metrics: up versus down time. maintenance costs, costs connected with modifications, and the like. In other words, we man age development based on operational performance within cost parameters. HOW the vendor provides cost-effective performance is less of a concern than the results of the effort.. . . The issue of business versus technical value is near and dear to our heart..., and one [ which we focus a great deal of attention. I guess I am surprised to learn that companies would contract with companies for their technical value, at the relative expense of business value. If anything, we err on the other side! If there is not clear (expected) business value (expressed quantitatively: number of claims processed, etc.) then we can’t launch a systems project. We take very seriously the “purposeful” requirement phase of the project, when we ask: “why do we want this system?” and “why do we care?” There have been several attempts to relate technical value and business value in a quantitative and meaningful way. For example, Humphrey, Snyder, and Willis (1991) note that by improving its development process according to the CMM “maturity” scale (to be discussed in Section 12), Hughes Aircraft improved its productivity by 4 to 1 and saved millions of dollars. Similarly, Dion (1993) reported that Raytheon’s twofold in crease in productivity was accompanied by a $7.70 return on every dollar invested in process improvement. And personnel at Tinker Air Force Base in Oklahoma noted a productivity improvement of 6.35 to 1 (Lipke and Butler 1992). However, Brodman and Johnson (1995) took a closer look at the business value of process improvement. They surveyed 33 companies that performed some kind of process improvement activities, and examined several key issues. Among other things, Brodman and Johnson asked companies how they defined Return on Investment (ROI), a concept that is clearly defined in the business community. They note that the textbook definition of return on investment, derived from the financial community, describes the investment in terms of what is given up for other purposes. That is, the “investment must not only return the original capital but enough more to at least equal what the funds would have earned elsewhere, plus an allowance for risk” (Putnam and Myers 1992). Usually, the business community uses one of three models to assess ROT: a payback model, an accounting rate-of-return model, and a discounted cash flow model. However, Brodman and Johnson (1995) found that the U.S. government and U.S. industry interpret ROT in very different ways, each different from the other, and both different from the standard business school approaches. The government views ROT in terms of dollars, looking at reducing operating costs, predicting dollar savings, and calculating the cost of employing new technologies. Government investments are also expressed in dollars, such as the cost of introducing new technologies or process improvement initiatives. On the other hand, industry viewed investment in terms of effort, rather than cost or dollars. That is, companies were interested in saving time or using fewer people, and their definition of return on investment reflected this focus on decreasing effort. Among the companies surveyed, return on investment included such items as: • training • schedule • risk • quality • productivity • process • customer • costs • business The cost issues included in the definition involve meeting cost predictions, improving cost performance, and staying within budget, rather than reducing operating costs or stream lining the project or organization. FIG. 6 summarizes the frequency with which many organizations included an investment item in its definition of ROT. For example, about 5 percent of those interviewed included a quality group’s effort in the ROI effort calculation, and approximately 35 percent included software costs when considering number of dollars invested. The difference in views is disturbing, because it means that calculations of ROI are incomparable across organizations. But there are good reasons for these differing views. Dollar savings from reduced schedule, higher quality, and increased productivity are re turned to the government rather than the contractor. On the other hand, contractors are usually looking for a competitive edge and increased work capacity as well as greater profit; thus, the contractor’s ROT is more effort- than cost-based. In particular, more ac curate cost and schedule estimation can mean customer satisfaction and repeat business. And decreased time to market as well as improved product quality are perceived as offering business value, too. Even though the different ROT calculations can be justified for each organization, it is worrying that software technology return on investment is not the same as financial ROT. At some point, program success must be reported to higher levels of management, many of which are related not to software but to the main company business, such as telecommunications or banking. Much confusion will result from the use of the same terminology to mean vastly different things. Thus, our success criteria must make sense not only for software projects and processes, but also for the more general business practices they support. We will examine this issue in more detail in Section 12 and look at using several common measures of business value to choose among technology options. 4. WHO DOES SOFTWARE ENGINEERING? A key component of software development is communication between customer and developer; if that fails, so too will the system. We must understand what the customer wants and needs before we can build a system to help solve the customer’s problem. To do this, let us turn our attention to the people involved in software development. The number of people working on software development depends on the project’s size and degree of difficulty. However, no matter how many people are involved, the roles played throughout the life of the project can be distinguished. Thus, for a large project, one person or a group may be assigned to each of the roles identified; on a small project, one person or group may take on several roles at once. Usually, the participants in a project fall into one of three categories: customer, user, or developer. The customer is the company, organization, or person who is paying for the software system to be developed. The developer is the company, organization, or person who is building the software system for the customer. This category includes any managers needed to coordinate and guide the programmers and testers. The user is the person or people who will actually use the system: the ones who sit at the terminal or submit the data or read the output. Although for some projects the customer, user, and developer are the same person or group, often these are different sets of people. FIG. 7 shows the basic relationships among the three types of participants. The customer, being in control of the funds, usually negotiates the contract and signs the acceptance papers. However, sometimes the customer is not a user. For example, suppose Wittenberg Water Works signs a contract with Gentle Systems, Inc., to build a computerized accounting system for the company. The president of Wittenberg may describe to the representatives of Gentle Systems exactly what is needed, and she will sign the contract. However, the president will not use the accounting system directly; the users will be the bookkeepers and accounting clerks. Thus, it is important that the developers understand exactly what both the customer and users want and need. On the other hand, suppose Wittenberg Water Works is so large that it has its own computer systems development division. The division may decide that it needs an automated tool to keep track of its own project costs and schedules. By building the tool itself, the division is at the same time the user, customer, and developer.
In recent years, the simple distinctions among customer, user, and developer have become more complex. Customers and users have been involved in the development process in a variety of ways. The customer may decide to purchase Commercial Off- The-Shelf (COTS) software to be incorporated in the final product that the developer will supply and support. When this happens, the customer is involved in system architecture decisions, and there are many more constraints on development. Similarly, the developer may choose to use additional developers, called subcontractors, who build a sub system and deliver it to the developers to be included in the final product. The subcontractors may work side by side with the primary developers or they may work at a different site, coordinating their work with the primary developers and delivering the subsystem late in the development process. The subsystem may be a turnkey system, where the code is incorporated whole (without additional code for integration), or it may require a separate integration process for building the links from the major system to the subsystem(s). Thus, the notion of “system” is important in software engineering, not only for understanding the problem analysis and solution synthesis, but also for organizing the development process and for assigning appropriate roles to the participants. In the next section, we look at the role of a systems approach in good software engineering practice. PREV. | NEXT |